With IBM MQ, the message payload is *always* a byte stream, but this does not mean you always have to deal with binary payloads in VSE. The MQ CCSID header is there to allow the automatic translation from bytes to text and back, and in 9.5.1 the override CCSID field is there to allow you use a different CCSID for this conversion. An MQ message payload is always ultimately sent and received as bytes, but in most cases you shouldn't have to deal with the bytes directly. Things are designed to handle text <-> bytes conversions as automatically as possible. If your application uses the CCSID header as it is intended then you don't even have to worry about character sets and byte streams.
> The kind of byte array which is getting published depends on the data type defined in the RIP/ROP files the application uses.
Does this mean that the same service can receive requests formatted either as ASCII or as EBCDIC? Trying to support both character sets in the same VSE service, without being able to use the CCSID header to tell us which one to use, complicates things quite a bit.
> What I'm suspecting is the code page I'm using might be wrong because when I googled, what I found is the EBCDIC code page for UK is Cp285. Not sure if this fix the issue.
The most common code pages I see for EBCDIC are 37 (Cp037) and 500 (Cp500). When I say "most common", I mean I cannot recall seeing anything else used until you mentioned 285 (a regional EBCDIC variant probably equivalent to 37/500 for your purposes) and 1047 (which I'm not sure is even EBCDIC).
> @Kevin- In 9.5.1 and later, the newer IBM MQ Native transport protocol has a built-in option to override the message's CCSID and use a different one for encoding/decoding the body. You can do this for both receiving requests and sending responses.. can you elaborate more on how can I do it at the VSI response level.
In 9.5.1+ with the IBM MQ Native transport protocol, there is a new meta-data property you can set on a VSI response: 'msg.overrideCharacterSet':
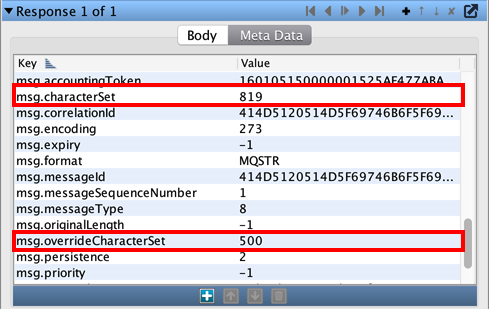
Even without this property, you can manually set the regular 'msg.characterSet' property to 500 and the message will be encoded as EBCDIC automatically. That works pre-9.5.1 and it works with the old IBM MQ Series transport protocol. Changing the CCSID of an outgoing response is very easy. You can use your scripted DPH to just set this meta-data property to whatever you want:
lisa_vse_response.get(0).getMetaData().setParameterValue("msg.characterSet", "500");
It's not as simple on the request side. You can set the override CCSID in the 'Listen' VSM step:

This will force all requests to be decoded as EBCDIC regardless of the CCSID given in their headers. However, this is only available in the IBM MQ Native transport protocol, and it doesn't work if a single service can receive requests encoded in *either* ASCII or EBCDIC.