While APM easily gives us hundreds or thousands of metrics for an application, and manages these metrics for up to a year... what are we really supposed to do with all that?
For sure, there will be the occasional triage event, so lots-O-metrics will probably be handy is sorting that incident. And we will of course want to alert on stuff. Other folks might be interested in managing application quality, from release to release. And then there is that whole DevOps chestnut and non-functional requirements.
But what do you really know about the application X, other than the fact that it generates like 5,283 metrics?
What are its startup characteristics? How does the volume of transaction vary from day to day? What should I be alerting on to get early notice of impending doom? How do I know that the application is behaving as expected or has moved into an unforeseen situation?
What you want is a ‘handle’ on the app. You want its signature. You want to know what makes this app the same, or different, from all the other apps that you are managing. What is the One Thing, or at least a couple things, that let you know the app is running great, or missing the mark. What is the mark anyway?
Key Performance Indicators – says who!!!
A KPI is a metric that has distinguished itself by being the ‘loudest’ or most significant, in contrast to all the other available metrics. For a well-known application, everybody will ‘know’ the most critical KPI – the business depends on it !! - but this comes with the benefit of operational experience. For a newly monitored app, or one that has been recently upgraded in performance and capabilities, you need to quickly identify candidate KPIs which you will validate as you get operational experience.
We divide KPIs into arbitrary categories, depending on organization maturity, that helps folks to transition from the historical comfort zone of platform monitoring and into the less familiar application and transaction monitoring contexts on which we ultimately manage and fund the lifecycle of a given software-based service. We say “comfort zone” because this is what IT folks are both most familiar with, and can independently and readily determine if they are operating within suitable ranges. One of the challenges with APM is that the operations perspective alone is not enough to know what the thresholds for certain metrics should be. IT needs to collaborate with the business and development to validate candidate KPIs and their associated thresholds.
So that’s a mouthful! Let’s break it down and fill in the story.
Here is the spectrum of KPIs that a typically under consideration:
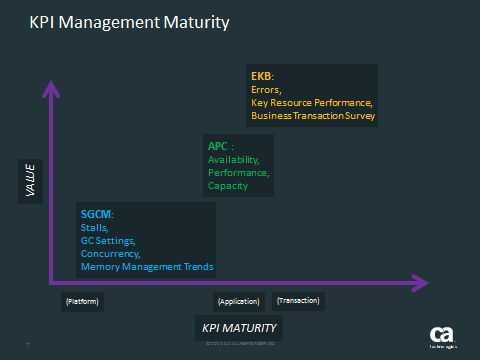
The acronyms are non-standard but serve to capture the types of metrics.
Traditional IT metrics are “SGCM”. These are elements that every application has and the ranges and dangerous trends are well known. These also are completely independent of what the app is actually doing, from a user or even business perspective. The benefit is that they don’t require any collaboration to understand if they are normal or abnormal. The detriment is that they have little or no meaning for the business, or pretty much any stakeholder you are likely to run into!
Depending on these metrics will generally bring about disappointment for the APM initiative.
“We spent all this money... to get the same stuff we were getting from ITCAM!!!”
Not a meeting I want to be in….
Application monitoring begins in earnest with “APC”. Of course IT folks will be managing availability as this has been a big deal for some 50 years already! And IT folks determine availability via platform monitoring – what’s this got to do with APM?!?!
Monitoring availability with APM is something we do to provide validation for the IT folks. It is something that we can do to confirm that when IT sees a problem, that APM also sees that same problem. We need to do this for IT folks to have confidence that APM can be “trusted”. And in that exercise, they will also start to realize that APM offers a great deal more information, even when monitoring something as simple as “availability”.
Monitoring performance is something that platform monitoring doesn’t do a super great job with but this has more to do with the component-level visibility of APM. If the performance info is coming via logs, or synthetics, APM will use that same information. But the dynamic instrumentation of APM is giving insight into response times that are not defined with synthetics or written to logs, which turns out to be really interesting in diagnosing performance issues or displaying transaction detail. It exposes relationships that were not obvious when the logging or synthetics we being coded.
Monitoring capacity is also done coarsely with platform monitoring and really gets fine detail via APM. This can also be a validation point, building confidence in APM, as well as pointing out unforeseen relationships from the volume perspective.
If we want to show value with APM then this is the area, APC, that we want to focus our KPI effort on. This is where APM begins to bring uniqueness of perspective while we are still not too far from traditional platform monitoring. This means it is still familiar and can be easily validated. It also starts the collaboration engine because picking KPIs is easy. Validating them requires some input from other stakeholders and this can be a process that is not well-establish for many clients.
The final grouping “EKB” is often completely outside of IT interests but firmly within the other stakeholders, especially the business. Of course IT folks are interested in errors… but not really. Show me an application that runs without errors.. and I’ll show you somebody who is not using APM! Do the errors affect availability? If “yes” – IT cares. If “no” – IT simply doesn’t care. If it is not indicative of a stability or performance degradation, it does not raise IT’s blood pressure – every app has some errors…
Where the errors have weight are in the End-user experience, something that APM exposes, and something that the business is really, really interested in. A couple hundred errors in the context of a couple million transactions - not really significant – except when most of those errors were from shopping carts that didn’t make it to “purchase”.
For the key resource performance, this also breaks down the same way. IT is managing the individual trees. The business is looking to optimize the forest: what types of tress are needed, at what volume to service their marketplace. As long as the trees are “up” – IT blood pressure is low. But if the business cannot get the right lumber, at the right time – overall software-based service objectives (aka revenue generation) are missed.
The real insight into “what types of trees” are needed – this is given by the business transactions. Understanding which transactions are significant – only the business knows. IT folks simply don’t have the insight. And this is where the collaboration has to be really strong in order to achieve effective performance management. It can bring the candidate transactions as ‘suspect’ and the business needs to confirm, or set aside. And this validation repeats until the key transactions are all identified and managed.
So where is this really going?
In all of this monitoring, IT is being moved a bit from their comfort zone, identifying and preparing information that ultimately is not a direct benefit for themselves. It is really for the benefit of the other stakeholders. This can be uncomfortable for IT folks to accept. They have always been the keeper of the monitoring tools and hold the keys to the source information on which they calculate their availability numbers, which is ultimately how they get resources (tools, staff, hardware) and beer money!
When we go down the KPI path we develop a signature that helps us understand how a given application is unique. That information is needed by all sorts of stakeholders who contribute to the application lifecycle and in optimizing the software-based business service that generates revenue. IT staff ‘needs’ only a fraction of this new APM information to do its job in managing the service infrastructure. They need a dashboard that lets them see issues ‘at a glance’, for sure. And the KPI process will help them define and validate that “operations Overview” dashboard.
The real destination for KPIs will be in the form of a baseline. This is a report format that lets the various stakeholders do trend analysis. It is a report that will get sucked into a spreadsheet. There will be lots of dashboards but they will be the spreadsheet kind, not the visual sort. It is really, really hard to trend ‘a picture’! You need numbers - lots of numbers. Sifting through those numbers will allow the business to better manage the application lifecycle, Design, Development, Testing and Operations – and improve software-based service quality.
Our job is to make getting those numbers easy. First, we have to help decide the best handful of metrics to send… NOT all 5,283 that might be available. Second, we need to facilitate a conversation with the business and validate. We talk to business folks all the time. IT folks? – not so much… Let’s show them how to start the conversation… with KPIs.
===================================
Hey wait a minute! Where are my quick KPIs!?
For those who can’t wait for the next post, here is a discussion paper that shows how to get KPIs with Introscope and move these along into alert thresholds and dashboards and reports.
Even better, go get my book, available on amazon. Don’t wait for blog posts! Put it on your kindle/eReader. Read it this summer… and dominate the APM sales and delivery cycle this fall.