What is "big data"?
It's the latest IT fashion trend! Everything else is **** - without a "big data" strategy! If you can't manage "big data", your business is doomed!
But seriously, "Big Data" is what Google and Facebook (and others) are doing - if it makes them successful - then it can make your business successful...somehow... but no one is exactly sure how, outside of Google and Facebook (and others).
"Big Data" is the buzzword. Analytics in the science. Data Warehousing is the Grandfather. Wait a sec! - how is this Big Data really different from data warehousing?
Data warehousing is the migration of various data sources, via ETL(Extract, Transform and Load" into a single, massive database against which you would construct ad-hoc SQL queries. Folks spent a lot of money to get to the point that they could do some analysis, largely based on SQL, and pull of unknown but valuable relationships in that data. Problems were many: data formats kept changing, data sources multiplied and, most significantly, RDBMS technology doesn't really scale to the degree needed. So folks really didn't get much return for the investment and ongoing maintenance. I'll even go so far as to make a contentious qualitative statement: If you're using relational technology alone, it ain't Big Data! See BigTable and Databus and Hadoop and form your own opinion.
What sets "Big Data" apart are the tools, and even APIs, that data sources like Google and FaceBook make available for anyone to do analysis on their data sets. They have a lot of practical experience but there is always room for more – so they want everyone in a position to contribute in extracting new relationships and analysis. For sure, analytics is an emerging technology and a heaping pile of tools are available to anyone. This is what sets Big Data apart from Data Warehousing: democratization of access and collaboration vs. the ivory tower of data warehousing. This is really what we need to do with our data - we need to make it easy for folks to access and undertake ad-hoc analysis.
What's big about APM data?
Lots of folks look at an APM Cluster and conclude: “Wow – that must be big data!!”
Considering that a typical cluster will manage upto 2800 JVMs and CLRs, managing up to 5M metrics every 15 seconds. This certainly meets the criteria for “big”! It is also a non-relation storage technology (based on HFS – from the sixties!) – so the scales are certainly tipping in favor of big data. And if you take a typical, national-scope portal application, something that is in multiple data centers; you will find yourself looking at 3-8 clusters worth of metrics. Surely there must be some gold in that mountain of data!!!
So what about relationships in this big pile of metrics?
What does time-series performance data really tell us about something interesting for the business? Can I do something with APM data, like I can with Google or Facebook or LinkedIn?
No. Not much. Really. It is just a stream of real-time measurements, updated every 15 seconds.
Of course we can use this data to draw inferences about the health and stability of an application, provided you give us one tiny bit of information. You have to tell us when something went wrong… and then we will go show you what led to that event. If you give us a valid event, like a trouble-ticket, we can use APM visibility to tell you how you got into trouble. This helps you solve the outage but it really doesn’t tell you anything about the application until you decide that something has gone wrong.
And of course we have a complementary technology called ABA that helps out in the detection of anomalous behavior – but you still have to complete the correlation, usually with an incident but always via a correlation with some data source external to APM!!!
So if you want to do some “Big Data”, you have got to make APM part of your strategy and integrate (I prefer the term 'enrich') multiple other data sources. The role of APM is to provide the temporal foundation on which to correlate and analyze the relationships that other resources help highlight and validate.
Here is a chart I use to introduce some of the other data sources that I use to validate what APM is telling me.
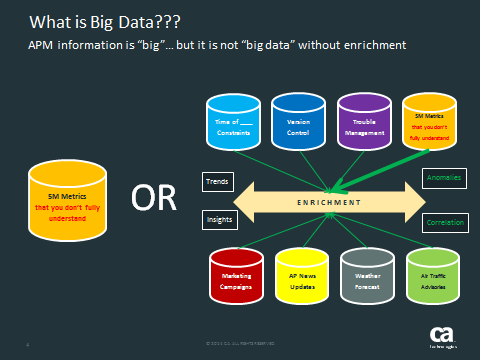
And this idea of enrichment is absolutely key to realizing anything useful with “Big Data”. Some folks may want to challenge me on this – so I’ll look forward to the comments. But the test is easy: just walk into a customer Network Operations Center! While you admire the manifold APM dashboards… look closely at some of the other feeds they are using. That CNN broadcast. The Weather Channel homepage. A network flow analyzer. This is “Big Data” in the wild. All the correlations are ad-hoc. You take in the scene and human nature (the part that is good at finding correlations) takes over. It is way more art than science but this is where we have to provide more value and direction, if we want to have a ‘real’ big data story. How do we make it easy for the NOC to absorb and use the realationships among these real-time information sources??? How do we take their observations and encode these into "Expert Systems" for doing network management???
What makes APM data different from other data sources?
Part of my thesis is that APM is the foundation for meaningful analytics that involve “Big Data”. Why is that? So here is another chart I use in my discussions:

The parts I’ve highlighted (Validation and Real-time) are two undeniable points. Validation; where we take an incident (on which everyone agrees) and show how the resources or application is to blame – this results in a confirmation to which other correlations may then be sought. In the real world this means I look at the deployment mechanisms, change control, etc. to drill into the root cause of what led to the incident. Software really doesn’t suddenly ‘break’. But it is usually evident, long before the incident, that there are problems that will lead to the failure of the software-based service.
As the other sources are very different, in terms of the temporal impedance, we have to have strong confidence in our assessment of the incident so that these other correlations, weeks before or weeks after, can also be validated and trended.
These trends are what the business and IT are trying to expose and exploit in order to improve the software-based services. We make it possible those stakeholders to get to root-cause but we do not yet make it easy. I think this is where “Big Data” thinking can help us to align or product and technical strategies to ensure that we can support meaningful root-cause analysis.
Another technique we employ to validate what we see with APM is to define a baseline among various KPIs (Key Performance Indicators). We make a definition of "normal" which we then compare to the incident, in order to confirm "abnormal". When you have baselines for all of the resources that comprise your software-based service, you are ready to "triage with baselines" - and you have a mighty fine time with APM! Baselines are a big topic... which I will defer until the next blog post.
Conclusion
So what does Big Data mean for APM? Opportunity - provided that you have a data source integration strategy, and an analysis workstation that lets you define and manage multiple baselines. APM is the foundation for validation and correlation in “Big Data” – provided that you have a variety of sources with which to enrich the timeline that APM documents.
===========
Can't wait for the next blog post? Can't handle my contentious and mildly pedantic prose? Here is the source presentation "Getting Value from Application Performance Metrics", as an attachment.