Greenplum Database, built on PostgreSQL and designed for massively parallel data processing, powers analytics at scale.
As with any large-scale distributed system, operability — the ability to observe, manage, and troubleshoot the system — is critical for long-term maintainability, ensuring uptime, and keeping the system healthy.
To streamline operational workflows, Greenplum introduces a Task Scheduler — a lightweight, internal framework designed to run service-oriented tasks at scheduled intervals.
Use cases range from scheduled execution of recurring tasks—such as running utilities like gprecoverseg to recover or rebalance segments, or performing disaster recovery activities like continuous data replication—can quickly become time-consuming and error-prone if done manually.
The Task Scheduler simplifies this process by enabling the automated, scheduled, and orchestrated execution of such workflows, thereby improving both reliability and operational efficiency.
Key Advantages of the Greenplum Task Scheduler Framework
- Task-based workflow orchestration using gRPC for performance
- User-friendly interface is developed by incorporating Customer familiar tools and practices, offering custom functionality for Greenplum users to reuse existing resources/infrastructure
- Email alert notifications to eliminates the need for regular monitoring by DBAs
- Flexibility to run user-defined pre- and post-setup checks/operations
- Broader Greenplum utility usage across all the componenets
- Extendable to add custom features, such as copying configuration files(pgbouncer) from primary to recovery site, enhancing current utility capabilities
This blog post explores its design, usage, and how it helps teams proactively operate/maintain the clusters at scale.
🚀 Why an Operability Task Scheduler?
Traditionally, regular operation workflow in Greenplum relied on ad hoc scripts or manual invocations (gpdr, gprecoverseg, gpbackup, gpmt, gpcheckcat etc.).
These steps are often performed ad hoc or via scripts outside of the database, leading to:
- Extra manual overhead for DBAs/SREs to recover the segment
- WAL build-up due to delayed segment recovery
- User table bloating due to delayed Vacuum
- Database outage and resulting application downtime were caused by insufficient monitoring and maintenance of critical database events
The Task Scheduler aims to resolve this by providing a structured way to:
- Schedule recurring tasks (e.g., gather_log_stats, check_disk_health, recover_failed_segments, regular_backup)
- Monitor and act proactively with commonly known issues like disk usage/database hang/bloat in the user table
- Alert DBA in case of a critical issue and take some predefined actions
- Unified Solution for various needs depending on the Customer requirement's.
- Enhance existing utilities and functionalities to support any custom DBA requirements.
The Task Scheduler addresses this by enabling internal and user-defined tasks to be run automatically and reliably within the Greenplum environment.
🧱 Design Overview
The Task Scheduler runs inside the Greenplum Coordinator Node and can communicate with the agents present in a segment. It supports cron-style schedule format so that existing scripts customers use can be configured here.
The Framework includes below components,
Task Registry : A catalog-based registry (gp_service_tasks_configuration.yaml) that stores the task definition and schedule.
Execution Engine : schedules tasks based on cron-style intervals.
Task Execution History: Stores execution history, which is preserved across host reboots
Logging : Various logging events for troubleshooting issues.
Tasks can be of various types, like
- One-time : Run once (gpservice task execute)
- Recurring : Scheduled via cron-style intervals
- Time-based : Periodic tasks via cron expressions
- Threshold-based/Reactive: Triggered based on some event like disk health, etc.
Example Tasks
Here are a few sample tasks that can be configured:
| Task Name |
Description |
Frequency |
| Auto Segment Recovery |
Recover the failed segment and rebalance Greenplum Cluster |
Hourly/daily as per need |
| collect_log_bundle |
Gathers logs from all segments |
Occurrence of some event/issue |
| check_disk_usage |
Verifies disk usage across segment hosts |
Hourly |
| catalog_consistency_check |
Checks for inconsistencies in catalog metadata |
Weekly |
| track_long_running_queries |
Captures active queries > threshold time |
Every 10 minutes/as per requirement |
⚙️ How It Works
The Task Scheduler framework is built for flexibility, allowing it to easily adapt to diverse user requirements. Its simple and intuitive design ensures a smooth transition from existing operational workflows, minimizing effort and disruption.
At its core, the scheduler accepts a user-defined task configuration as input in the yaml format. From there, users can easily pause, resume, execute, or monitor the status of tasks, depending on operational requirements.
The gpservice task utility helps to manage this framework, and more details can be found in the Greeplum documentation↗︎.
A task typically moves through the following stages:
- Schedule a Task – Define and register the task with a schedule.
- Pause a Task – Temporarily disable execution without deleting it.
- Resume a Task – Reactivate a previously paused task.
- Execute a Task – Run the task manually, regardless of schedule.
- Monitor Task Status – View task execution history, status, and various other task stats.
- Unschedule/Delete a Task – Remove the task entirely from the scheduler.
└─❯ gpservice task
Logs can be found at: /var/log/greenplum-7/gpservice_task_20250709.log.
Greenplum serviceability task scheduler
Usage:
gpservice task [flags]
gpservice task [command]
Available Commands:
environment Display the current task environment
execute Instantly execute the configured gpservice task
export Display current gpservice tasks configuration in yaml format
pause Pause the scheduled gpservice tasks
resume Resumes the configured gpservice tasks operation
schedule Add, update and delete gpservice tasks
status Display execution status of configured gpservice tasks
Flags:
-h, --help help for task
Global Flags:
--verbose Provide verbose output
Use "gpservice task [command] --help" for more information about a command.
The diagram below illustrates the complete lifecycle of a task and how it transitions between various states.
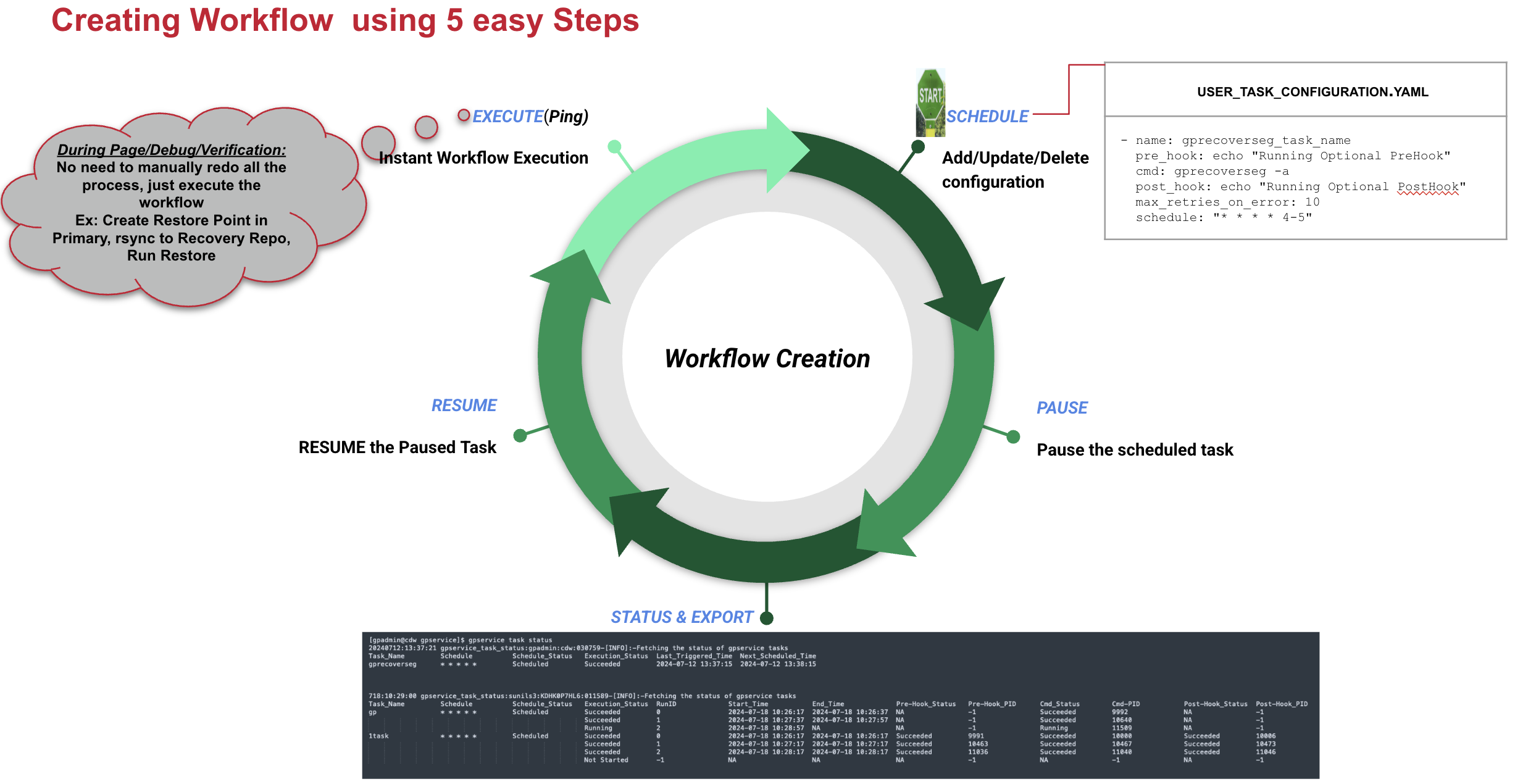
Figure: Lifecycle of a task
i. Schedule task:
The schedule command(gpservice task schedule) allows you to add, update, or remove tasks based on a user-provided task configuration file. By default, any newly added task is immediately scheduled according to its defined cron expression.
To get started, create a configuration file that specifies the task details. You can refer to the official documentation for guidance and examples:
A sample task configuration file is given below.
gpservice_user_task_configuration.yaml |
Examples of Pre-hook and Post-hook are
- Determining Greenplum Segment Status and Recovering It
pre_hook: Use a command to check the status of Greenplum database segments (For example, with gpstate -e) to determine if any segments are down.
cmd: Automatically recover down segments using the gprecoverseg utility. This ensures that recovery actions are triggered only when segments are down, improving the reliability of the cluster without manual intervention.
- Creating Backups and Copying Data
pre_hook: Perform preparatory tasks such as verifying cluster health or validating disk space before taking a backup.
cmd: Use gpbackup to create a backup of a specified database or table.
post_hook: Transfer the backup data to a secure location using rsync or similar tools, ensuring data safety and accessibility.
To schedule a new task, define it in your task configuration YAML file and run:
💲 gpservice task schedule --config-file /path/to/task/config/file/gpservice_task_configuration_template.yaml
This will register and schedule the task as per its configuration.
Note:
If the original configuration file is lost, you can regenerate it using the following command:
gpservice task export > current_task_config.yaml
The Task Scheduler framework maintains a single unified configuration file, so exporting will capture the current state of all scheduled tasks.
ii. Pause Task:
If a scheduled task needs to be temporarily paused—such as during a maintenance window—you can use the pause command without having to delete the task. This can be done either for specific tasks (by name) or for all currently scheduled tasks.
If a task is already running, the scheduler provides different options to gracefully or forcefully stop it, depending on the situation. For more details on supported pause modes, refer to the official documentation.
# Pause all scheduled task
💲 gpservice task schedule --config-file /path/to/config.yaml --pause-all
# Pause a single/multiple task
💲 gpservice task schedule --config-file /path/to/config.yaml --pause "sample_task_1,sample_task_2"
This puts the task into pause state from a scheduled state.
iii. Resume Task:
If a previously paused task needs to be resumed—such as after a completed maintenance window—you can use the resume command. This allows the task(s) to continue running according to their original schedule without needing to recreate or reconfigure them.
You can resume either specific tasks (by name) or all paused tasks at once using the available flags.
# Resume all paused tasks
💲 gpservice task schedule --config-file /path/to/config.yaml --resume-all
# Resume a single or multiple tasks
💲 gpservice task schedule --config-file /path/to/config.yaml --resume "sample_task_1,sample_task_2"
This transitions the task from a paused state back to the scheduled state, enabling it to run as per its defined schedule.
iv. Monitoring Task Status (status)
The status command is used to display the execution status of all configured gpservice tasks. It helps monitor both currently running and past executions, providing insight into task behavior and troubleshooting.
To view the current status of all scheduled tasks:
💲 gpservice task status
To check the status of specific tasks only:
💲 gpservice task status --name task_name1,task_name2
To display extended details, including the status of the last 9 executions and more information about any currently running tasks:
💲 gpservice task status --detail
NOTE: Logs for failed or problematic task runs can be found at: /var/log/greenplum-<version>/gpservice_hub_<timestamp>.log

─❯ gpservice task status --detail
Logs can be found at: /var/log/greenplum-7/gpservice_task_status_20250709.log
Task_Name Schedule Schedule_Status RunID:Execution_Status Previous_Triggered_Time Start_Time End_Time Next_Scheduled_Time Pre-Hook_PID:Status Cmd_PID:Status Post-Hook_PID:Status
autorecover_task * * * * * Scheduled 24:Failed 2025-07-09 21:12:44 2025-07-09 21:13:49 2025-07-09 21:13:51 2025-07-09 21:14:51 5366:Succeeded 5378:Failed NA
25:Failed 2025-07-09 21:13:49 2025-07-09 21:14:55 2025-07-09 21:14:58 2025-07-09 21:15:58 6346:Succeeded 6352:Failed NA
26:Failed 2025-07-09 21:14:55 2025-07-09 21:16:02 2025-07-09 21:16:03 2025-07-09 21:17:03 7185:Succeeded 7191:Failed NA
27:Failed 2025-07-09 21:16:02 2025-07-09 21:17:08 2025-07-09 21:17:10 2025-07-09 21:18:10 7794:Succeeded 7805:Failed NA
coordinator_failover_task * * * * * Scheduled 24:Succeeded 2025-07-09 21:12:39 2025-07-09 21:13:44 2025-07-09 21:13:45 2025-07-09 21:14:45 5333:Succeeded 5340:Succeeded 5346:Succeeded
25:Succeeded 2025-07-09 21:13:44 2025-07-09 21:14:50 2025-07-09 21:14:52 2025-07-09 21:15:52 6075:Succeeded 6081:Succeeded 6088:Succeeded
26:Succeeded 2025-07-09 21:14:50 2025-07-09 21:15:57 2025-07-09 21:15:59 2025-07-09 21:16:59 6918:Succeeded 6924:Succeeded 6930:Succeeded
27:Succeeded 2025-07-09 21:15:57 2025-07-09 21:17:04 2025-07-09 21:17:05 2025-07-09 21:18:05 7571:Succeeded 7577:Succeeded 7587:Succeeded
check_catalog_health_task * * * * * Scheduled 24:Failed 2025-07-09 21:12:44 2025-07-09 21:13:49 2025-07-09 21:13:50 2025-07-09 21:14:50 5367:Succeeded 5379:Failed NA
25:Failed 2025-07-09 21:13:49 2025-07-09 21:14:54 2025-07-09 21:14:56 2025-07-09 21:15:56 6104:Succeeded 6110:Failed NA
26:Failed 2025-07-09 21:14:54 2025-07-09 21:16:01 2025-07-09 21:16:02 2025-07-09 21:19:16 8243:Succeeded 8249:Failed NA
v. Instant Execution:
If you want to run a task immediately, without modifying its regular schedule, you can use the execute command. This allows a one-time execution of the task while still preserving its defined schedule.
This is especially useful when you want to:
- Test a task using its existing configuration
- Manually trigger a task during debugging or troubleshooting
- Perform an ad-hoc run without rewriting or duplicating workflows
Run a specific task immediately
💲 gpservice task execute --name sample_task_1
This command triggers the task once without affecting its scheduled execution timeline.
vi. Unschedule Task:
If a configured task is no longer needed, it can be removed either individually or by clearing all configured tasks using the appropriate commands.
To delete Specific Task(s)
To delete one or more tasks, remove the corresponding entries from the configuration file and run the schedule command:
💲 gpservice task schedule --config-file /path/to/config.yaml
To delete All Configured Tasks
To remove all scheduled tasks in one go:
💲 gpservice task schedule --delete-all
🧩 Extending the Framework
Greenplum’s Task Scheduler provides flexibility by allowing administrators to plug in custom scripts or commands at various points of task execution using the prehook, cmd, and posthook fields.
These hooks support a variety of formats, including Shell scripts (.sh), Python or Go binaries, Inline terminal commands, and many others.
This makes it easy to integrate custom logic, validations, environment setup, cleanup routines, or credential handling into the workflow — all without modifying the core task behavior.
Example:
Let’s say you want to perform a backup operation, but before that, you need to mount a remote storage drive and set environment variables. You can use a prehook script for this:
- name: backup_task
pre_hook: "/home/gpadmin/scripts/setup_backup_env.sh"
cmd: "/opt/scripts/run_gpbackup_or_gpdr.sh backup"
post_hook: "echo 'Backup completed at $(date)' >> /var/log/backup_status.log"
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
💡 Real-World Use Case:
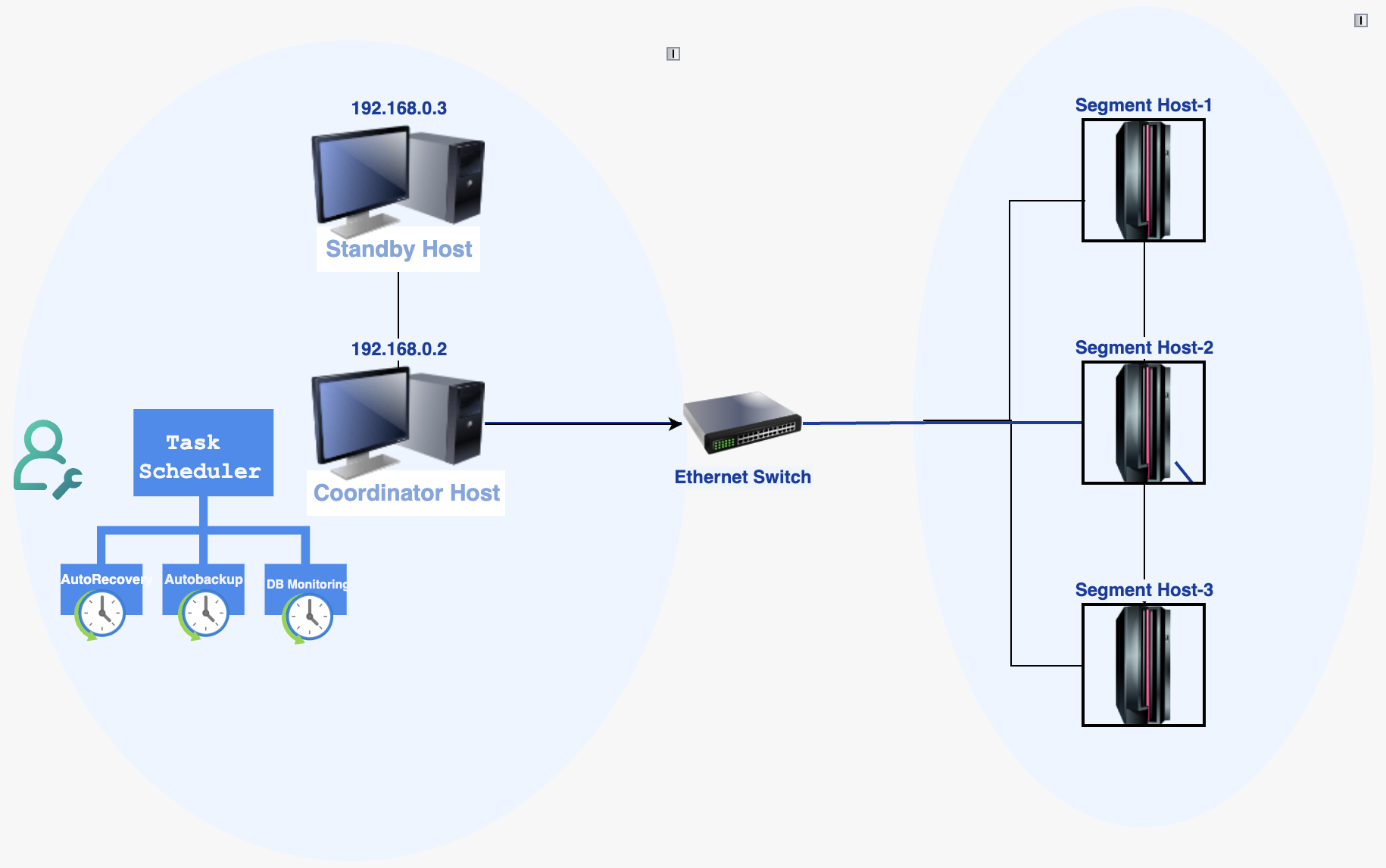
1. AutoRecover Failed Segments
Issue: Intermittent issues cause Greenplum segments to go down, requiring DBAs to manually recover and rebalance failed mirrors/primaries using gprecoverseg.
Impact: This manual process is an overhead for DBAs, who need to constantly monitor and rebalance the cluster.
Solution: Task framework can be used that monitors and automatically recovers failed segments, saving DBAs time and effort. DBAs would be notified of all failures, and if an error is continuous rather than intermittent, they can take immediate action without delay.
2. Autobackup and Auto Restore
Issue: Manual backups can be time-consuming, error-prone, and may be missed if not consistently monitored, especially in large or production environments.
Impact: Missing or delayed backups increase the risk of data loss and reduce recovery reliability during outages or failures.
Solution: Use gpbackup/gpdr to automate backup operations as part of a scheduled task using Greenplum’s Task Scheduler. This ensures backups are performed reliably and consistently, without manual intervention.
Example:
Create a task that runs gpbackup nightly via the Task Scheduler to maintain a robust backup strategy.
3. Auto catalog check
Issue: Over time, inconsistencies can accumulate in the Greenplum system catalog due to software bugs, improper shutdowns, or unexpected system events. These issues often go undetected until they cause failures during operations like upgrades, backups, or DDL changes.
Impact: Undetected catalog corruption can lead to data integrity issues, failed operations, and complex recovery efforts. It may also delay critical activities like cluster upgrades or expansions.
Solution: Automate regular catalog consistency checks using gpcheckcat with the Greenplum Task Scheduler. This ensures early detection of catalog issues, enabling proactive remediation and improving overall system health.
Example:
Schedule a weekly gpcheckcat run using a task configuration, and route results to logs or monitoring systems for visibility.
check_cluster_health.sh↗︎
#!/bin/bash
DBNAME="<database-name>"
SYSTABLES="' pg_catalog.' || relname || ';' FROM pg_class a, pg_namespace b
WHERE a.relnamespace=b.oid AND b.nspname='pg_catalog' AND a.relkind='r'"
reindexdb --system -d $DBNAME
psql -tc "SELECT 'VACUUM' || $SYSTABLES" $DBNAME | psql -a $DBNAME
analyzedb -as pg_catalog -d $DBNAME
Below is the sample task configuration snippet
- name: catalog_health_task
pre_hook: "/home/gpadmin/scripts/check_cluster_health.sh"
cmd: /path/to/catalog_maintenence_script.sh
post_hook: mailx -s "Regular Catalog activity is success" < /dev/null "gpadmin@dba.com"
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
4. Continuous Replication
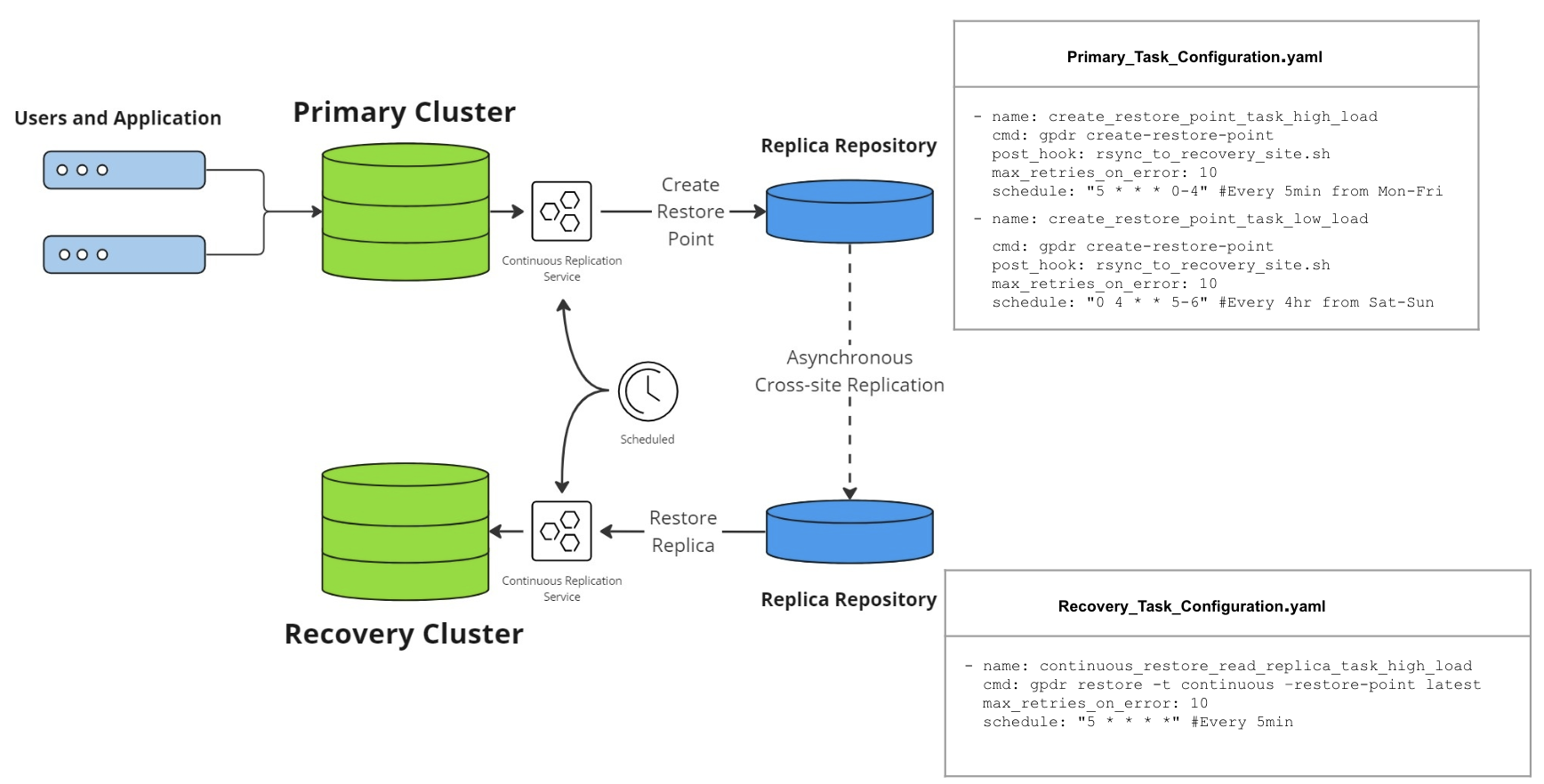
Figure: Continuous Replication Workflow
Issue: RTO (Recovery Time Objective) and RPO (Recovery Point Objective) indicate the time taken to promote the recovery cluster to production status after a primary crash. “Storage is expensive.” How to clean up restored files ?.
Impact: Having a larger delta increases the application downtime.
Solution: Automating the backup and restore workflow would ease the burden on customers. Automating regular cleanup helps to save storage space.
At Production Cluster, create a task configuration to create a restore point.
- name: backup_task
pre_hook: "/home/gpadmin/scripts/check_cluster_health.sh"
cmd: gpdr create-restore-point --suffix="task_scheduler"
post_hook: gpdr backup --type incremental
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
Similarly, at Recovery Cluster, create a task configuration to restore incrementally.
- name: backup_task
pre_hook: "/home/gpadmin/scripts/check_repo_access.sh"
cmd: gpdr restore --type incremental --restore-point lastest
post_hook: echo "Successfully completed restore"
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
5. Disaster Recovery Failover and failback
With Custom scripts, we can automate/orchestrate the required failover/failback workflow activities that DBA performs as part of regular maintenance/POC.
6. Routine System Monitoring and Maintenance Task
Regular maintenance tasks such as cleaning up unused data, clearing cache, or executing custom scripts are essential for keeping the database healthy and performant. These operations can be automated using routine tasks, as outlined in the Greenplum Maintenance Guide.
With the Greenplum Task Scheduler, you can automate many of the repetitive administrative operations described in the official documentation:
i. Monitoring Guide↗︎
ii. Maintenance Guide↗︎
iii. System Health Monitoring↗︎
For example, you can monitor transaction ID (XID) usage and take automated action before hitting the limit(Greenplum 6X), reducing risk of system downtime. The Task Scheduler can help enforce preventive measures and automate recovery steps as documented in the section: Recovering from a Transaction ID Limit Error↗︎.
7. Custom Retention Policy development(auto cleanup)
When a new backup is created, older backups may become obsolete. If these are not removed promptly, they can accumulate and significantly increase disk usage, potentially leading to additional storage costs. To avoid this, you can configure a post-hook to automatically expire or clean up outdated backup files.
- name: backup_with_cleanup_task
pre_hook: "/home/gpadmin/scripts/check_repo_access.sh"
cmd: gpdr restore --type incremental --restore-point lastest
post_hook: gpdr expire backup --backup-label 20220919-122516F --dr-restore-point 20231121-172843R
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
8. Expand the Functionality of Existing Utilities
Issue: Built-in utilities may not cover all custom operational or functional requirements specific to your environment.
Impact: Lack of flexibility can lead to manual workarounds, increased maintenance overhead.
Solution: Use the post-hook feature to seamlessly extend existing utility behavior without altering its internals. For instance, after completing a standard backup, a post-hook script can automatically copy custom configuration files (e.g., to a remote repository), enabling tailored workflows while preserving utility integrity.
- name: backup_task
pre_hook: "/home/gpadmin/scripts/check_cluster_health.sh"
cmd: gpdr backup --type incremental
post_hook: cp $COORDINATOR_DATA_DIRECTORY/some_custom.conf $archive_repository
log_command_error : true
log_command_output : false
schedule: "0 2 * * *"
9. Proactive Log Collection During Failures
Issue: Unexpected WAL buildup, query hangs, or out-of-disk-space conditions may occur in a Greenplum cluster, impacting system stability and performance.
Impact: Delayed log collection during such incidents can lead to incomplete diagnostics, increasing the time required for root cause analysis (RCA) and resolution.
Solution: By configuring the Greenplum Operability Scheduler to automatically trigger a collect_log_bundle task upon detecting such issues, critical logs can be captured proactively. This early collection improves diagnostic accuracy and significantly reduces RCA time.
10. Workload-Driven Operational Task Scheduling
Issue: Operational maintenance tasks like vacuuming or creating restore points are often scheduled statically, without considering varying workload patterns.
Impact: Fixed scheduling can lead to unnecessary resource contention during peak hours or missed optimization opportunities during idle periods, potentially causing performance degradation or table bloat, or some miscellaneous issues.
Solution: Use the task scheduler to define workload-aware maintenance tasks that adapt based on your system load. For example, increase the frequency of vacuum or restore point creation during high workload periods to maintain RTO(Recovery Time Objective) or RPO(Recovery Point Objective) and reduce task frequency during off-peak hours to conserve resources. This dynamic approach aligns maintenance with actual usage patterns based on your Application's needs.
🛠 Troubleshooting guide:
To effectively troubleshoot or monitor the behavior of the Task Scheduler, Greenplum provides several diagnostic mechanisms and logging touchpoints.
Below are key ways to gather detailed insights:
-
Framework Logging via gpservice
The gpservice task command-line tool automatically generates logs based on the configuration specified in the gpservice init file and task configuration log parameters. This includes log level and log destination settings. Refer to the official gpservice documentation for guidance on configuring logging parameters.
-
Subcommand-Specific Logs
Each subcommand of the gpservice task (e.g., schedule, pause, status, execute) creates a dedicated log file. These logs are stored under the default gpservice log path(/var/log/greenplum-<version>/gpservice_<sub_command>_<timestamp>.log)
These logs help you isolate issues specific to a particular operation or task command.
-
Scheduler Hub Logs
The core scheduling logic is managed by the GPService Hub. To troubleshoot scheduling issues (e.g., missed executions, cron parsing errors), examine the Hub
log(/var/log/greenplum-<version>/gpservice_hub_<timestamp>.log)
This log contains detailed execution flow, task scheduling decisions, and runtime hooks.
-
Task Execution History
You can also inspect task execution history and statuses using the following command:
This provides information such as task state (e.g., scheduled, paused, failed), last run time, and exit codes. Reviewing execution history helps pinpoint recurring failures or unexpected task behaviors.
Summary
The Greenplum operability Task Scheduler empowers teams to:
- Automate repetitive management and cluster operations.
- Increase observability across distributed segments
- Enable proactive system maintenance
- Monitoring custom user requirements
As Greenplum continues to evolve, its built-in tooling like this ensures that scale doesn’t come at the cost of manageability.
In the future, many features will be added to the existing framework. Stay tuned till then......
References:
Greenplum Task Scheduler gpservice manual
Monitoring Greenplum System
Recommended Monitoring and Maintenance Tasks
Recovering Failed Segment