Thanks LeslieBNS9. I believe we are experiencing similar causation.
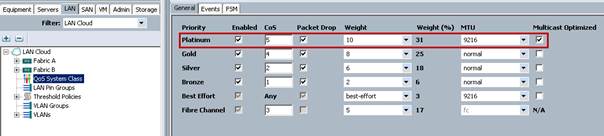
Instead of uplinking our UCS servers directly to switches first they connect to the Fabric Interconnects 6248s, which then uplink to Nexus 7010s via (2) 40GE vPCs. The Fabric Interconnects are discarding packets as evidenced by "show queuing interface" on all active vSAN interfaces. The manner in which we have vmnics situated in VMware (Active/Standby) Fabric B is effectively dedicated to VSAN traffic, and the cluster is idle so not a bandwidth issue or even contention, rather the FI's scrawny buffer assigned to custome QoS System Classes in UCS not able to handle bursts. We have QoS configured per the Cisco VSAN Reference doc. Platinum CoS is assigned qos-group 2, which only has a queue/buffer size of 22720! NXOS in the UCS FIs is read-only so this is not configurable.
I will probably disable Platinum QoS System Class and assigning VSAN vNICs to Best Effort so we can at least increase the available queue size to 150720
Ethernet1/1 queuing information:
TX Queuing
qos-group sched-type oper-bandwidth
0 WRR 3 (Best Effort)
1 WRR 17 (FCoE)
2 WRR 31 (VSAN)
3 WRR 25 (VM)
4 WRR 18 (vMotion)
5 WRR 6 (Mgmt)
RX Queuing
qos-group 0
q-size: 150720, HW MTU: 1500 (1500 configured)
drop-type: drop, xon: 0, xoff: 150720
qos-group 1
q-size: 79360, HW MTU: 2158 (2158 configured)
drop-type: no-drop, xon: 20480, xoff: 40320
qos-group 2
q-size: 22720, HW MTU: 1500 (1500 configured)
drop-type: drop, xon: 0, xoff: 22720
Statistics:
Pkts received over the port : 256270856
Ucast pkts sent to the cross-bar : 187972399
Mcast pkts sent to the cross-bar : 63629024
Ucast pkts received from the cross-bar : 1897117447
Pkts sent to the port : 2433368432
Pkts discarded on ingress : 4669433
Per-priority-pause status : Rx (Inactive), Tx (Inactive)
Egress Buffers were verified to be congested during large file copy:
show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
The following command reveals congestion on the egress (reference):
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0x1
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0x2
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
nap-FI6248-VSAN-B(nxos)# show hardware internal carmel asic 0 registers match .*STA.*frh.* | i eg
Slot 0 Carmel 0 register contents:
Register Name | Offset | Value
car_bm_STA_frh_eg_addr_0 | 0x50340 | 0
car_bm_STA_frh_eg_addr_1 | 0x52340 | 0
car_bm_STA_frh_eg_addr_2 | 0x54340 | 0
car_bm_STA_frh_eg_addr_3 | 0x56340 | 0x1
car_bm_STA_frh_eg_addr_4 | 0x58340 | 0
car_bm_STA_frh_eg_addr_5 | 0x5a340 | 0
car_bm_STA_frh_eg_addr_6 | 0x5c340 | 0
car_bm_STA_frh_eg_addr_7 | 0x5e340 | 0
I should note we are not seeing discards or drops on any of the 'show interface' counters.