Thanks Zach for fast reaction.
We have opened SR in Vmware: What we know for now after VMware engineer investigation:
Report after troubleshooting first MGT cluster:
"It appears SSD naa.5001e8200282f398 on host XXXXXXXXXXXX experienced a hardware issue:
### vmkernel.log ###
2016-04-27T07:47:14.165Z cpu2:32803)NMP: nmp_ThrottleLogForDevice:2349: Cmd 0x1a (0x412e8089cf00, 0) to dev "naa.5001e8200282f398" on path "vmhba0:C0:T0:L0" Failed: H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0xcd 0x0. Act:NONE 2016-04-27T07:47:14.165Z cpu2:32803)ScsiDeviceIO: 2363: Cmd(0x412e8089cf00) 0x1a, CmdSN 0x107 from world 0 to dev "naa.5001e8200282f398" failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x4 0xcd 0x0.
Sense key 0x4 translates to "Hardware Error".
ASC/ASCQ 0xcd 0x0 is not listed on www.t10.org (http://www.t10.org/lists/asc-alph.htm), so I can't say what further information the RAID controller actually supplied here. I assume this value is vendor specific in this case.
Besides that I only see "I/O error" and " "Disk naa... not found in healthy state" messages in the logs for the disks.
As the SCSI error with sense data 0x4 0xcd 0x0 was only reported for one of the two SSDs, I'm not sure why the 2nd SSD didn't get mounted either.
It might still be related though. Looking at the used HBAs, there is only 1 RAID controller used, correct? So if there is a hardware issue with the controller itself actually, and not just SSD naa.5001e8200282f398, this might have a knock-on affect on the other disks as well.
Hence, my recommendation is to open a ticket with the hardware vendor, Dell, to investigate the hardware error further."
What is interesting day after this we had that same warning in second CMP (compute) cluster.
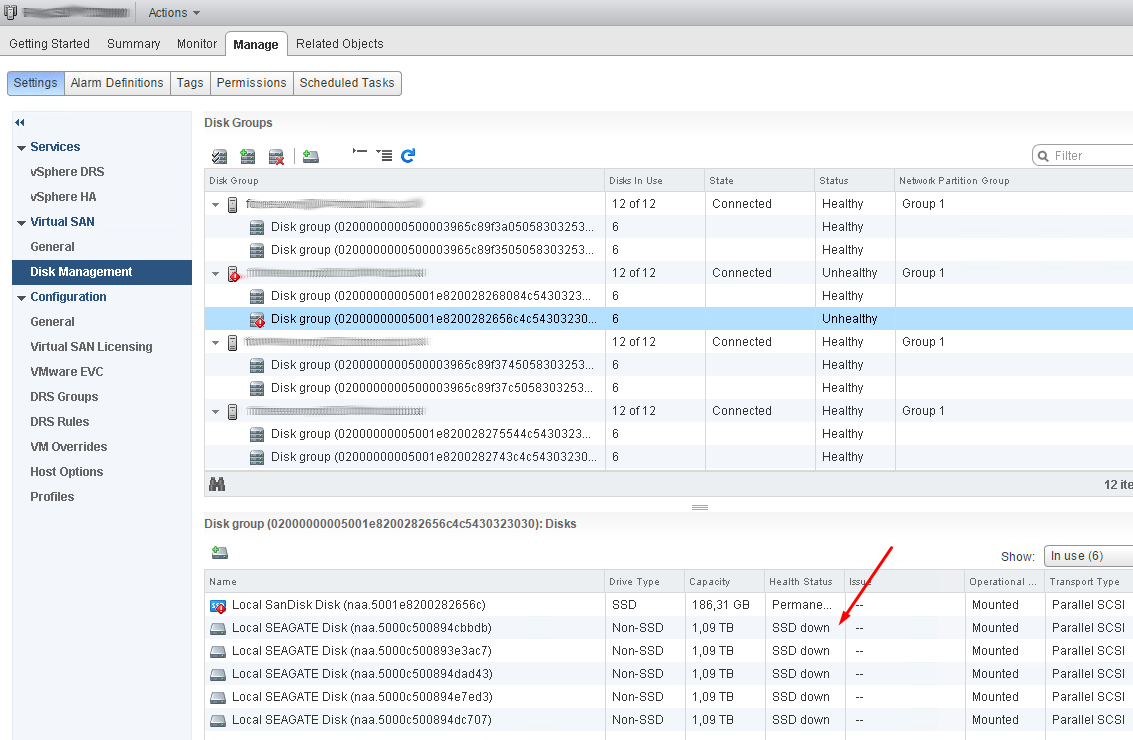
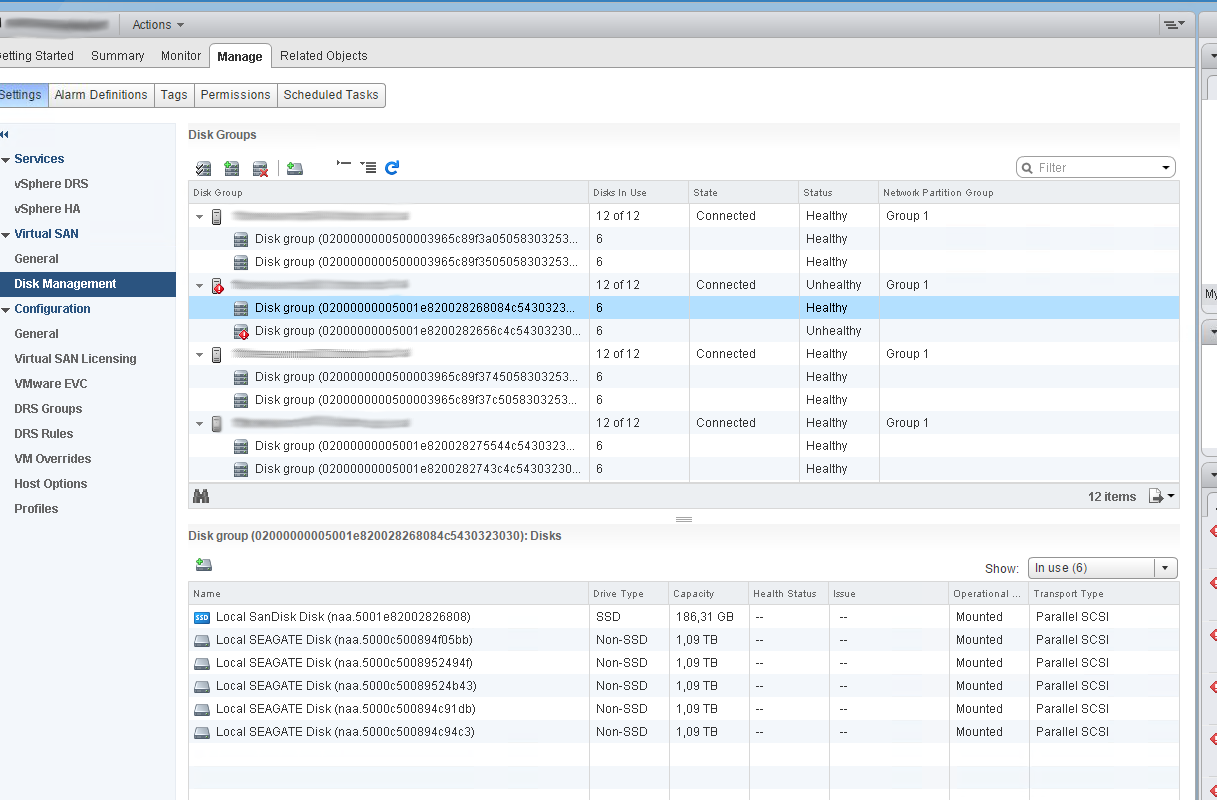

We found in logs many entries:
========= vmkernel.log ==============
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e803f0180) 0x2a, CmdSN 0x19998ae4 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f07305fc0) 0x2a, CmdSN 0x19998aec from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e8040c940) 0x2a, CmdSN 0x19998aed from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f22113180) 0x2a, CmdSN 0x19998b10 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e8040cbc0) 0x2a, CmdSN 0x19998afc from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f3ce16bc0) 0x2a, CmdSN 0x19998b07 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x2 0x3a 0x1.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e80426ac0) 0x2a, CmdSN 0x19998afe from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.364Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e803c51c0) 0x2a, CmdSN 0x19998b0d from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e803dbb00) 0x2a, CmdSN 0x19998b11 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412e8044ec00) 0x2a, CmdSN 0x19998af9 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)NMP: nmp_ThrottleLogForDevice:2349: Cmd 0x2a (0x412f092e3a00, 0) to dev "naa.5001e8200282656c" on path "vmhba0:C0:T0:L0" Failed: H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0. Act:EVAL
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f092e3a00) 0x2a, CmdSN 0x19998aeb from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f0b331d00) 0x2a, CmdSN 0x19998b06 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f0a43c440) 0x2a, CmdSN 0x19998ae3 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f0afaa5c0) 0x2a, CmdSN 0x19998af8 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f3ce14dc0) 0x2a, CmdSN 0x19998b13 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:26:02.365Z cpu26:20552761)ScsiDeviceIO: 2363: Cmd(0x412f08f26600) 0x2a, CmdSN 0x19998af1 from world 0 to dev "naa.5001e8200282656c" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
We tried manually mount drives without success:
esxcli vsan storage diskgroup mount -s naa.5001e8200282656c
In this issue helps server reboot....
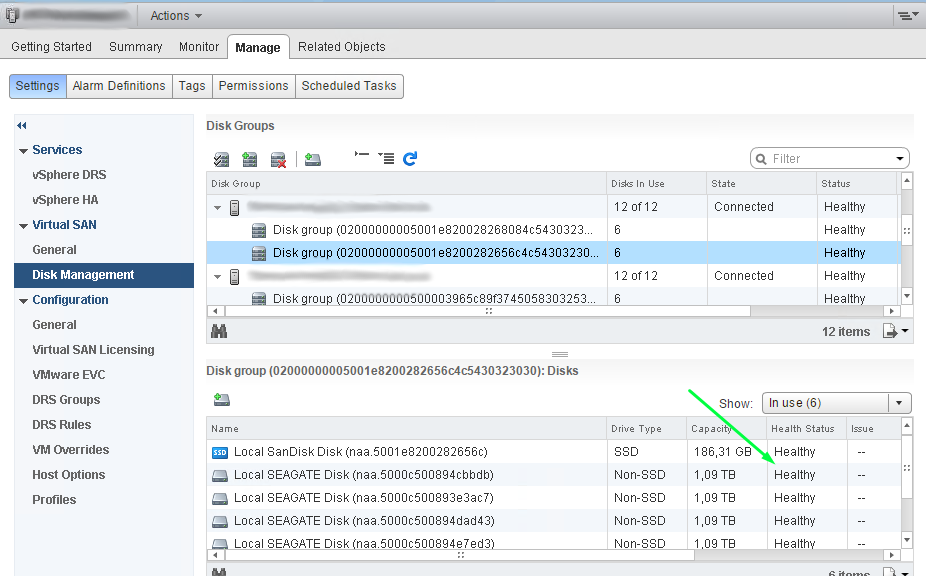
Unfortunately still i dont know why "Health status" is not showing up in one Disk Group. Maybe somebody know ?
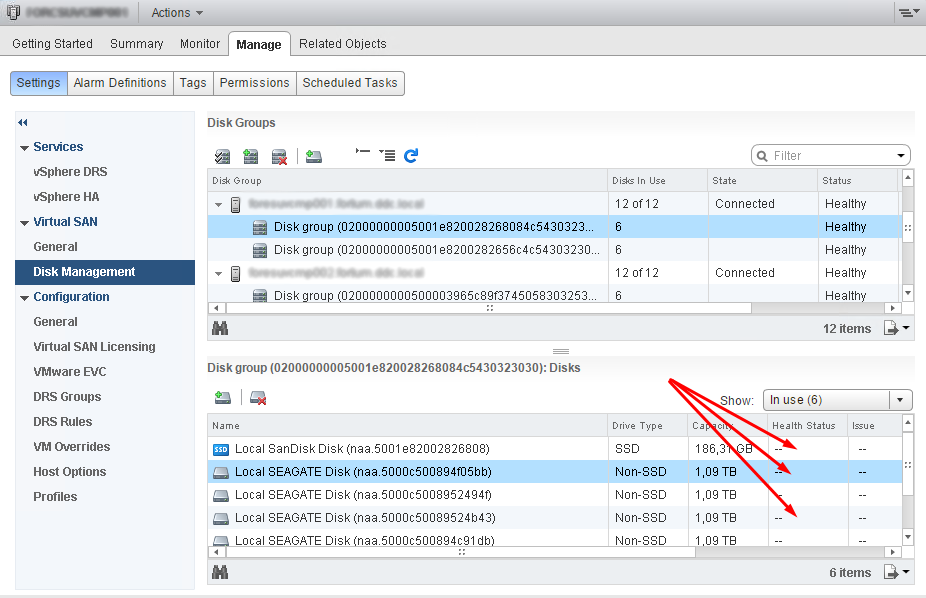
After this we receive short description from VMware engineer:
"H:0x5 (Aborts) on the affected host XXXXXXXXXX:
2016-04-28T09:27:31.280Z cpu42:27106261)ScsiDeviceIO: 2363: Cmd(0x412f4b776ac0) 0x28, CmdSN 0x7bcc36e9 from world 0 to dev "naa.5001e82002826808" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:27:31.280Z cpu48:27106244)ScsiDeviceIO: 2363: Cmd(0x412f4b773280) 0x28, CmdSN 0x7bcc36e2 from world 0 to dev "naa.5001e82002826808" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:27:31.280Z cpu42:27106261)ScsiDeviceIO: 2363: Cmd(0x412f4b771fc0) 0x28, CmdSN 0x7bcc36e7 from world 0 to dev "naa.5001e82002826808" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
2016-04-28T09:27:31.280Z cpu29:27106294)ScsiDeviceIO: 2363: Cmd(0x412f4b775a80) 0x28, CmdSN 0x7bcc36e6 from world 0 to dev "naa.5001e82002826808" failed H:0x5 D:0x0 P:0x0 Possible sense data: 0x5 0x20 0x0.
Prior to that we could see megasas aborts in the vmkernel logs.
This particular issue is described in the following KB article: http://kb.vmware.com/kb/2109665
One of the main steps to resolve this on a long term basis, is to increase the values for /LSOM/diskIoTimeout and /LSOM/diskIoRetryFactor (exact steps are also described in the mentioned KB article):
esxcfg-advcfg -s 100000 /LSOM/diskIoTimeout
esxcfg-advcfg -s 4 /LSOM/diskIoRetryFactor"
-------------------------------------------------------------------------------------------------
Case is still open because now we will create additional case in DELL to investigate hardware in first cluster which still have issue(reboot dont helps).
And in second cluster we still dont see Health state of disks in one Disk group.
I will inform about additional investigation.