Hello,
What you are writing is partialy right. Have you ever tested file copy on low end array ?
I get more throughput using a 60 magnetic disks in sequential read / write than in a full flash vsan cluster.
But it's as you said, the vsan is here to serve many "customers" not only my benchmark, whereas the low end array will go all in for me.
I think the main problem here is to accept the fact that, in a vsan cluster, you may get less performances on one job with hundred of flash disks working than you would get on a single direct attachment flash disk (or even local raid 5 raid card with 3 flash disks). It's disappointing but it's by design.
And it's good to know it - one VM can't compromise the whole vsan storage cluster.
What's the most frustrating I think is no bottleneck is seen in the chain.
Check data disks : latency ok
Check cache disks : latency ok and not filled up
Check network cards : way below full bandwitdh
Check switchs : underutilized
Check vsan : no bottleneck in graphs
Also some graphs doesn't make sense to me, and that is frustrating too.
But I believe the global vsan graphs are not accurate : it's related to our discussion. The vsan graphs show an average performance of VMs doing IOps.
And if at a specific point of time, only one VM is doing high IOPS : this VM will make the graphs "averages" go crazy.
Typical exemple : the backups.
Look at this (I removed writes as they are not spiking and it's easier to read and get my point) :
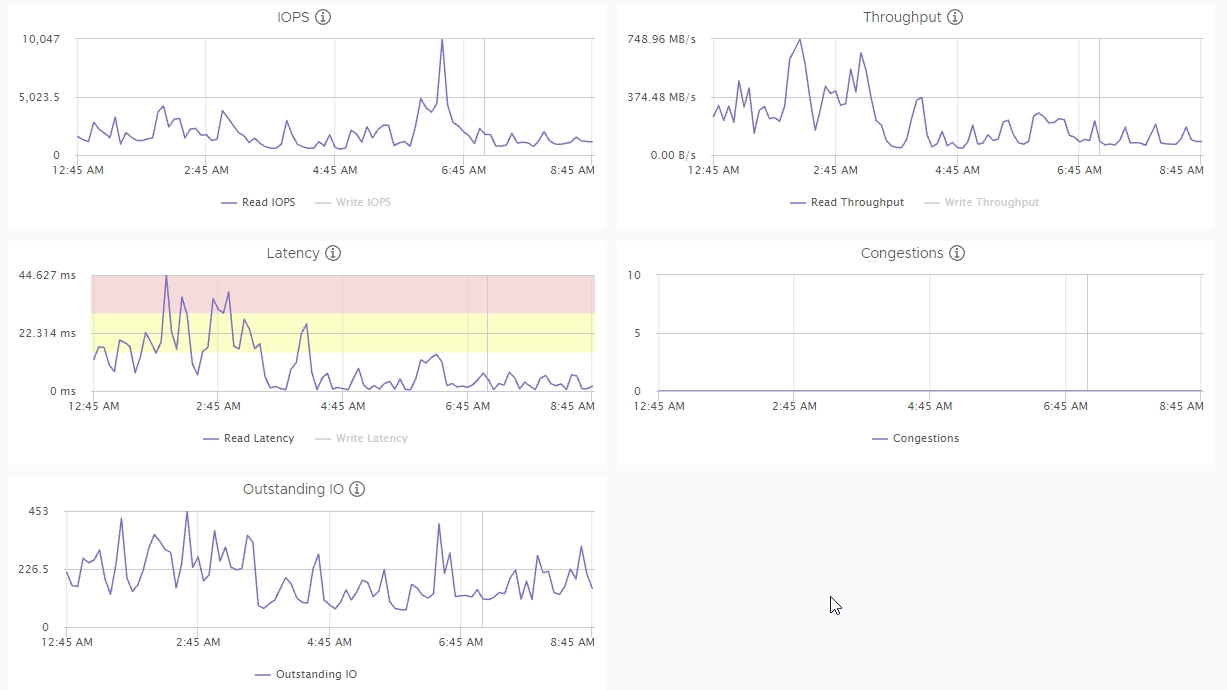
We see huge spikes in read latency while iops don't raise, but throughput do raise. So it's the sign of increasing IO size incoming on the vsan.
It's typical of backup jobs, reading big chunks.
You can see later an iops read spike while latency don't increase this much.
At first I thought there was a problem of latency in my vsan, but in fact there is no problem : just one VM doing a lot of stuff and result in "false average" latency graph.
I believe that, if during this backup time, I had many VMs doing "normal" iops (at least 3 or 4 more than the backup job), my graphs would show "normal" latency, not such spikes.
I don't know how this could be fixed.