by Reji Thomas and Bhasker Reddy
This article discusses the shared libraries concept in both Windows and Linux, and offers a walk through various data structures to explain how dynamic linking is done in these operating systems. The paper will be useful for developers interested in the security implications and the relative speed of dynamic linking, and assumes some prior cursory knowledge with dynamic linking.
Part one introduced the concepts for both Linux and Windows and focused primarily on Linux. Now in part two, we'll discuss how it works in Windows and then continue compare the two environments. Readers are encouraged to review part one again before continuing with this article.
Windows Portable Executable File Format (PE) data structures
We know that a section is a chunk of code or data that logically belongs together, and that the data for an executable's import tables are in a section. In this part of the article, we look at some of the sections found in Windows PE files.
Exports section (.edata)
The .edata section begins with the export directory structure IMAGE_EXPORT_DIRECTORY. The export directory contains RVAs (relative virtual addresses) of the: Export Address Table: This contains address of exported entry points, exported data and absolutes. An ordinal number is used to index the address table. The ORDINAL BASE must be subtracted from the ordinal number before indexing into the table.
Export Name Table Pointers: This array contains address in the Export name table. The pointers are relative to the image base and are ordered lexically to enable binary search. The export name table contains ASCII names for exported entries in the image.
Export Ordinal Table: The export name table pointers and Export ordinal table form two parallel arrays .The export ordinal table array contains the ordinal associated with the exported name referenced by the Export name table pointers. The ordinal will serve as the index into the EAT.
Imports Section(.idata)
The .idata section does the converse of what the .edata section, described above, does. It maps symbols/ordinals back into RVAs. The .idata begins with a import directory table IMAGE_IMPORT_DIRECTORY .The import directory table consists of an array of IMAGE_IMPORT_DESCRIPTOR structures, one for each imported executable. The IMAGE_IMPORT_DESCRIPTOR contains RVAs of :
Import Lookup Table: This is an array of IMAGE_THUNK_DATA structures .The structure contains ordinal or hint/name RVAs for each imported function. The table identifies the symbols to import, with the entries in the import lookup table being parallel to those in the Import Address Table (IAT). If the high bit of an entry is set , the lower bits are the ordinal. Otherwise the entry is a RVA of an entry in the hint-name table.
Import Address Table: This is also an array of IMAGE_THUNK_DATA structures. Initially both the Import Lookup table and the IAT contain similar entries. The loader fills in the addresses of each of the imported routines in this table, while the entries in the Import Lookup Table retains the original data as before. We will see why the linker maintains the original information later when we discuss binding.
Hint-Name Table: The table consists of a 4-byte hint followed by the null terminated symbol name. The hint value is used to index the Export Name Table pointers array, allowing faster by-name imports. The hint will be right if the DLL hasn’t changed or at least its list of export symbols hasn’t changed. If hint is incorrect, then binary search is performed on the Export Name Pointer table.
How things work
Loading a Windows executable and DLL is similar to loading a dynamically linked ELF program in Linux. The difference is that here the linker is a part of the kernel itself. First the kernel maps in the executable guided by the PE headers. The loader looks at the IAT of the module and determines whether the DLL depends on additional DLLs, and if so the loader maps them also. This process continues until all of the dependent modules have been mapped into memory.
An imported function can be listed by name or it can be listed by ordinal. The ordinal represents its position in the DLL Export Address table. If listed by name, the loader does a binary search of the Export Name Pointers table of the corresponding DLL to lookup the index at which the symbol is found. It then uses that index as an index into the Export Ordinal table to get the ordinal which, in turn, is used as an index into the Export Address table. Adding the RVA of the symbol found from the EAT to the load address of the corresponding DLL will yield the absolute address which the loader writes into the corresponding entry in the IAT.
Delay loading in Windows
A delay loaded DLL has a structure ImgDelayDescr similar to the .idata data import directory structure but it is not in the .idata section. The ImgDelayDescr contains the addresses of an IAT and an INT for the DLL. These tables are identical in format to the normal import ones, but they are written to and read by the runtime library code rather than by the operating system. When you call an API from a delay loaded DLL for the first time, the runtime library loads the DLL (if needed), gets the address, and stores it in the delayload IAT so that future calls go directly to the API.
A walk through through the Windows lazy linking procedure
In this section we will trace how the linker resolves the function address defined in a delay loaded DLL, as well as the semantics of making function calls where the function is defined in a DLL.
 Figure 7. Linker resolving the function address in a delay loaded DLL.
Figure 7. Linker resolving the function address in a delay loaded DLL.In the above case, fndll1() is defined inside d111(delay load) and fndll2 is defined inside d112.If you notice the declarations, fndll1() has been explicitly declared as __declspec(dllimport). The __declspec(dllimport) function modifier tells the compiler that the function resides in another DLL. The compiler takes the clue and generates code CALL DWORD PTR [xxxx], where xxx is an entry within the IAT.
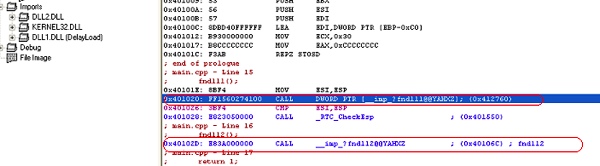 Figure 8. Compiler generates code CALL DWORD PTR [xxxx], where xxxx is an entry in the IAT.
Figure 8. Compiler generates code CALL DWORD PTR [xxxx], where xxxx is an entry in the IAT.
In the case of fndll2(), the compiler emits a call instruction of the form CALL xxxxx, where xxxx points to a stub. This results in an extra jump instruction, taking a longer time to execute.
 Figure 9. Extra jump instruction takes more time to execute.
Figure 9. Extra jump instruction takes more time to execute.
As shown in Figure 8, the fndll1() call results in a CALL DWORD PTR[0x412760] . Then 0x412760 is the address of the first entry in the Delayimport address table as seen below in in Figure 10.
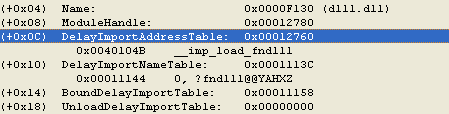 Figure 10. Finding the address of the first entry in the Delayimport address table.
Figure 10. Finding the address of the first entry in the Delayimport address table. This entry points to a helper routine that finds and loads the DLL, and then replaces the content of the address table with the actual address.
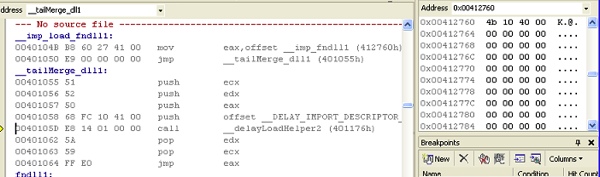 Figure 11.
Figure 11.
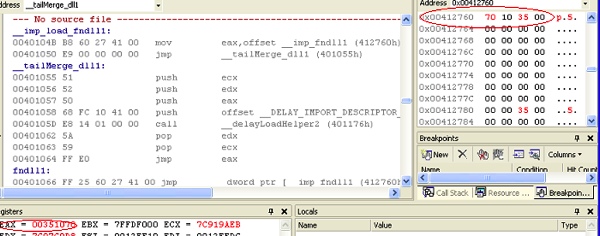 Figure 12.
Figure 12.
As you can see above, the address 0x412760 which earlier pointed to 0x40104b, which was the helper routine address, got overwritten by the loader with 0x351070, the address of fndll1 as seen below in Figure 13.
 Figure 13. Helper routine address is overwritten.
Figure 13. Helper routine address is overwritten.
Inside the Delay Load Helper
Windows allows you to add your own delay load helper routine. We will now trace what typically happens inside the helper routine. The reader should notice the marked similarities the lazy linking procedure has with its Linux counter part.
Let’s start by looking again at Figure 9. If you notice, you can see that linker inserts two types of stubs. One is of the type __imp_load_(function name) and other is __tailmerge_(dllname). As seen from the naming convention, the first type of stub is generated per API for the DLL and second type per DLL.
In Figure 9, the instruction does a jump to the __imp_load_(function name) stub through the Delay import address table. In the stub, the first instruction is:
Mov eax,offset __imp_fndll1
This moves the address of the zeroth entry of the Delay IAT. (Note that this is the address where the helper routine has to update with the resolved address of the routine). The next instruction is a jump to the DLL specific stub __tailmerge_(dllname). In the __tailmerge_ stub, after preserving the registers ecx and edx, it does a push of the eax.The next instruction is:
Push offset __DELAY_IMPORT_DESCRIPTOR_Dll1
This pushes the address of ImgDelayDescr struct of the DLL1.The data structure is defined in DELAYIMP.h
typedef struct ImgDelayDescr { DWORD grAttrs; // attributes LPCSTR szName; // pointer to dll name HMODULE * phmod; // address of module handle PImgThunkData pIAT; // address of the IAT PCImgThunkData pINT; // address of the INT PCImgThunkData pBoundIAT; // address of the optional bound IAT PCImgThunkData pUnloadIAT; // address of optional copy of original IAT DWORD dwTimeStamp; // 0 if not bound, // O.W. date/time stamp of DLL bound to (Old BIND) } ImgDelayDescr, * PImgDelayDescr; typedef const ImgDelayDescr * PCImgDelayDescr;
Now the function does a jump to the helper routine with these values in the stack as arguments. From now onwards, we will base our discussion based on the helper code defined in DELAYHLP.CPP:
__delayLoadHelper(PCImgDelayDescr pidd, FARPROC * ppfnIATEntry)
The delayLoadHelper first tries to get the module handle from the ImgDelayDescr.
//Calculate the function index, which is an index into the IAT.
iINT = IndexFromPImgThunkData(PCImgThunkData(ppfnIATEntry), pidd->pIAT);
As said before the IAT and INT are two parallel structures:
//Using the function index to point to the corresponding index at the INT. PCImgThunkData pitd = &((pidd->pINT)[iINT]);
//Get the function name or ordinal from the INT depending on whether the higher bit is set as discussed before.
if (dli.dlp.fImportByName = ((pitd->u1.Ordinal & IMAGE_ORDINAL_FLAG) == 0)) { dli.dlp.szProcName = LPCSTR(pitd->u1.AddressOfData->Name); } else { dli.dlp.dwOrdinal = IMAGE_ORDINAL(pitd->u1.Ordinal); } If (hmodule =0) //the first time { // Load library // Copy handle to the global variable(Call Free library() // if another thread got there before us) }
Now we must lookup the address of the procedure by calling GetProcAddress(), as was mentioned above in the explanation of how things work:
pfnRet = ::GetProcAddress(hmod, dli.dlp.szProcName);
We update the IAT entry with the address:
*ppfnIATEntry = pfnRet; //Back in __tail_merge_dll1
Now the eax contains the return value which is the resolved function address. Finally, the code does a:
Jmp eax // jump to the function.
Explicit Dynamic Linking
Both Linux and Windows provide routines (such as dlopen() and dlsym() in Linux, and LoadLibrary() ,GetProcAddress() in Windows) to explicitly load a library and to find the address of a routine in that library. These routines are just wrappers which in turn call the dynamic linker routines which were previously called at the time of implicit linking through the PLT or IAT.
Speeding things up – Static Linked Shared Libraries
Shared libraries in practice can be very slow. The performance degradation in using them happens mainly because of runtime loading and address binding, indirect references to the routine addresses through intermediate tables, and machine register reservation for these tables. Today with large address spaces, it’s possible to bind a library to a chunk of address space at the linktime itself and also resolve the address references. If the address space is available at runtime, relocation can be avoided. Libraries where program and data addresses are bound to executables at link time are referred to as static linked shared libraries.
Prelinking in Linux
Glibc is the only shared library in Linux which can be statically linked. For other options, Linux instead uses a similar concept called prelinking. A prelink assigns a unique virtual address slot for each library the executable depends on, and relinks the library to that base address.
Prelinking a shared library means identifying which other shared libraries are needed by this library, and pre-patching the shared library file by assuming that the needed shared libraries will be loaded at their selected pre-relocation addresses. Prelink also stores a list of all dependent libraries together with their timestamps and checksums into the library or binary.
 Figure 14. List of available libraries.
Figure 14. List of available libraries.
If you dump a prelinked executable or shared library, one thing which you will notice is the change in relocation format. Normally IA-32 architectures use only the REL format, where the relocation addend is stored at the offset address only. The only case where you might see a RELA section in IA-32 will therefore be here.
Since the prelinked shared libraries need to be usable even in non-prelinked executables, the addend information has to be preserved. To do this, a prelink converts the .rel.dyn section to RELA format. Prelink avoids doing this in cases where the addend is zero by changing relocation type to R_386_GLOB_DAT.
 Figure 15. Preserving the addend information.
Figure 15. Preserving the addend information.
The prelink utility also generates a conflict list during the prelink process and stores it inside the executable. The ELF document specifies that undefined symbols in shared libraries must be first searched in the main executable program, then searched in the needed shared libraries. Not all symbols resolve the same when looked up in a shared library's search scope (as is done when the shared library is prelinked) and when looked up in the application's global symbolsearch scope. Such symbols are called conflicts, and relocations against those symbols conflicting relocations.
The conflicting relocations are added in a separate RELA section in the executable. In this case, the Sym.name+addend will contain the actual address of the conflicting variable (in other words, resolved with respect to the global scope of the executable).
 Figure 16. Resolving conflicts.
Figure 16. Resolving conflicts.
At runtime, the dynamic linker first checks whether all dependant libraries were successfully mapped into their designated address space slots and whether they have not changed since prelinking was done. If it was, the prelinker has to do only a few adjustments which were defined by the conflict list created earlier.
Rebasing and binding in Windows
To look at the equivalent in Windows, Windows DLLs use the rebasing and binding concept. Every executable and DLL module has a preferred base address which identifies the address where the module should be mapped in the process address space. For an executable, the default value is 0x00400000 and for a DLL it is 0x10000000. This mean that if the executable is linked to two DLLs, one of them will have to be relocated in memory. To avoid this you can rebase your DLL by giving it a preferred address at the time of compilation. You can do this by passing the /base [address] switch in the project options.
As we have seen, win32 executables have two identical tables containing the information needed to lookup an imported function – the Import Name table and Import Lookup table. Only one copy is required by the loader. Bind takes advantage of this fact and overwrites the IAT entries with the imported function's actual address at link time. The bind adds bind information such as a timestamp to the bound executable. At loadtime, the loader verifies that the location of the symbol referenced in the DLL's exported section has not changed.
For checking the validity of the bound information, PE uses a data structure IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT which is pointed to by the data directory. This structure is a list of IMAGE_BOUND_DESCRIPTOR elements, one for each imported DLL. This structure stores the time stamp, the name of the imported DLL, and the number of forwarder references. The export forwarding concept is beyond the scope of this article. But for the sake of completion, it's good to know that Windows allows you to reference an exported API in one DLL which has been forwarded by that DLL to another one.
 Figure 17. The IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT data structure.
Figure 17. The IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT data structure.
If the DLL's time stamp has not changed, it uses the address that bind has stored in the IAT. Otherwise, it uses the hint/name table information to do the normal lookup.
Conclusion
The purpose of this article was to discuss the shared libraries concept in both Linux and Windows, by offering a walk-through various data structures that explain how dynamic linking is done. ">Previously in part one we introduced the concepts and then looked primarily the Linux way of doing things.
Here in part two we took a closer look at dynamic linking in Windows, including the lazy linking process and the Delay Load Helper. We looked briefly at how we can speed up the use of shared libraries, which are often slow in real life. Then we looked at prelinking in Linux and its equivalent in Windows, rebasing and binding.
It is hoped that this two-part article series has given readers a better insight into dynamic linking overall. The authors encourage readers to leave technical comments for this article in the comments section below.
References
- Linkers and Loaders by John Levine.
- Glibc-2.3.3 source code.
- Prelink by Jakub Jelinek, RedHat Inc
- Inside Windows An In-Depth look into the Portable Executable File format, part2
- The MSDN Library
- UNIX Man pages
About the authors
Reji Thomas is an associate software engineer with Symantec Corp, and his interests include mathematics, information security, compilers and financial modeling. Bhasker Reddy is also an associate software engineer with Symantec Corp; his interests include compilers, system programming, and operating systems.
Comments?
The comments section of this article is to be used for technical clarification and discussion only. Submitted comments must have technical merit in order to be approved.
This article originally appeared on SecurityFocus.com -- reproduction in whole or in part is not allowed without expressed written consent.