What could the mainframe industry possibly do with Generative AI? With this question, I began my journey into the world of mainframe modernization. Almost 2 months into my Summer Internship 2023 at Broadcom, the answer revealed itself – the possibilities are nothing short of extraordinary. As a matter of fact, they are no different from any other industry that incorporates Generative AI with a goal to create and own value for the business. From revolutionizing creative content to streamlining business processes, Generative AI has found its way into virtually every function. Treading on this path, I contributed to two projects centered around code generation.
Data Engineering for an Automated Unit Tests Generator
Aren’t we all tired of writing test cases and ensuring our code passes the SonarQube or some other static code analysis tool? In the second project I had the opportunity to contribute to a proof-of-concept which is to train a model to auto-generate test cases from code functions. The possibilities are exciting. It could ensure comprehensive scenario coverage, suggest tricky edge cases, and eliminate redundant or invalid tests. Testing would become fast, thorough, and efficient.
Data Collection Approaches and Challenges
Even though the model architectures have become task agnostic, realizing this vision requires curating task-specific data to train effectively. We have collected function and test pairs in Java, Python and C. Collecting C data was quite challenging since there are not many C tools in the ecosystem as it is very difficult to parse and represent the source code. We tried a few approaches.
- Hand crafted - Manual creation of functions and their test cases assisted by LLMs like ChatGPT. Tedious and limited scale.
- Transpiling - Transpiling existing Python/Java datasets into C code via LLMs. Only ~300 basic test cases were gathered.
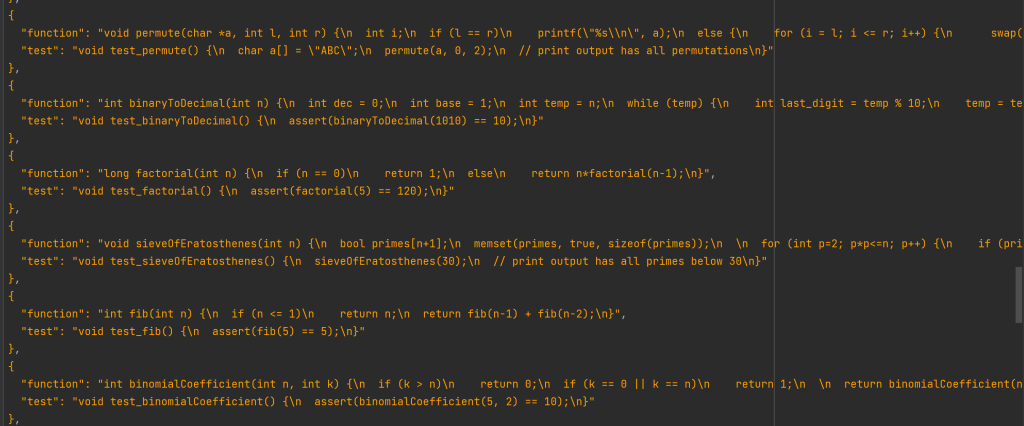 A sample of dataset generated using handcrafted and transpiler capabilities.
A sample of dataset generated using handcrafted and transpiler capabilities.
- Scraping C code repositories on GitHub – We used Regex to extract functions from the scraped repositories. The results were better but many pairs were missed due to lack of generalizability.
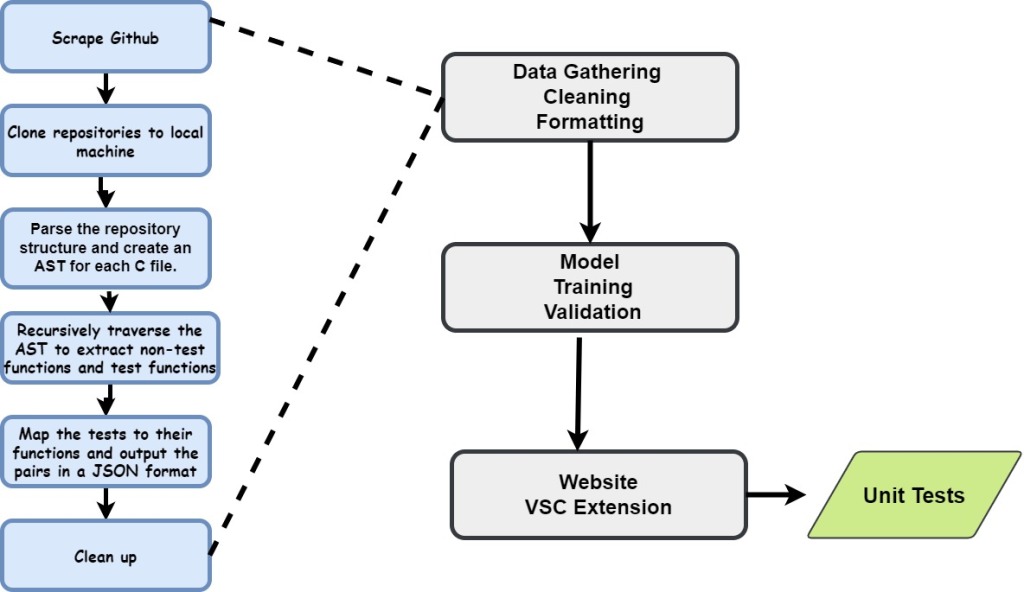 The Data Pipeline The Big Picture
The Data Pipeline The Big Picture
Clang, a frontend for C in LLVM to the Rescue
Clang provides a language front end and a tooling infrastructure for the languages of C family. I leveraged Clang’s parsing abilities to construct an abstract syntax tree (AST) for each C file. This allowed me to extract functions in a semantically and syntactically correct way. Since parsing fails on syntactic errors, using an AST ensures code quality of the data. It also enabled deeper code comprehension by providing valuable metadata such as variable types, function arguments, function calls. It abstracts away the language syntax details and thus simplifies developing the parser and programmatically analyzing the code. Further, the few functions missed out in the parser using REGEX were covered using the AST based parser.
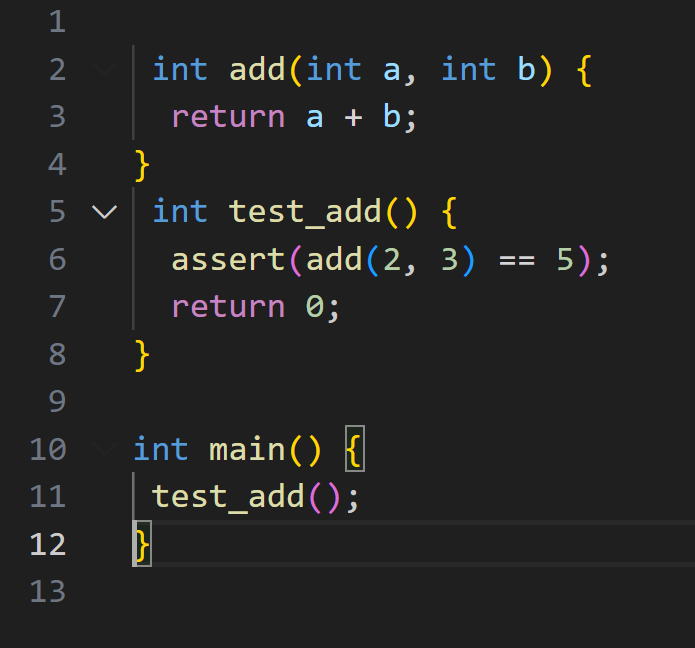 A sample C file
A sample C file
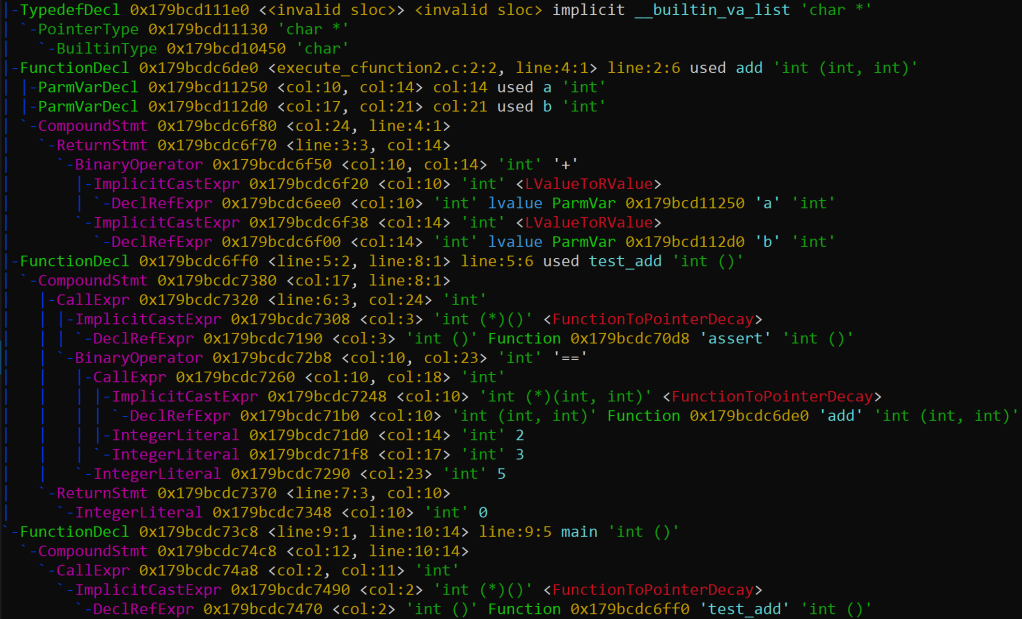 AST Constructed for the sample C file
AST Constructed for the sample C file
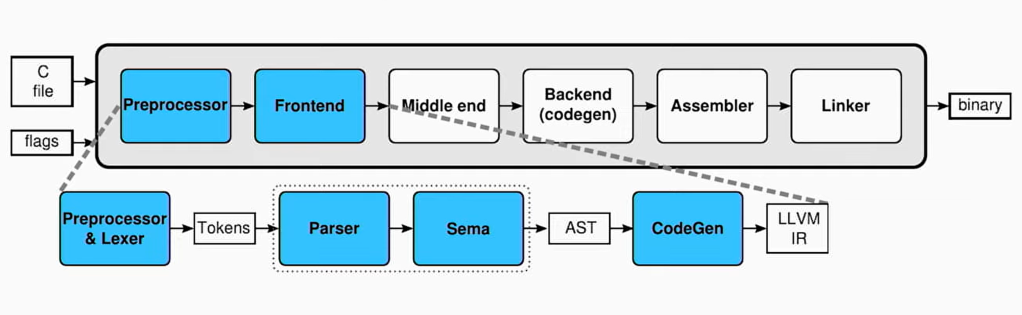 Understanding the core components of the Clang compiler driver. [Image source]
Understanding the core components of the Clang compiler driver. [Image source]
RESults and the road ahead
The number of functions, tests extracted from a randomly selected C repository and their successful pairing is shown in the following table. The result provides a strong evidence that the AST based approach has shown significant improvement over the REGEX based parser.
|
Functions |
Tests |
Function-Test Pairs |
| REGEX Based Parser |
9028 |
256 |
59 |
| AST Based Parser |
37714 |
661 |
3036 |
This is a view over a small set of repositories. I ran the pipeline over 18k repositories and have collected around 37k pairs.
Through this project, I learned to adapt and respond to change effectively rather than rigidly following a predetermined plan. With the help from my mentors, I pivoted to new and improved approaches. Developing this flexibility and willingness to iterate was a key takeaway that will serve me well in future.
A multi-pronged approach combining automated web mining with manual verification and expansion has provided diverse training data. The promise of liberating developers from mundane testing grunt work motivates me. I am eager to refine our data pipeline, datasets, models - getting us closer to the day where bugs and regressions are caught before code ever ships and enabling developers to focus more on creative tasks.
Pair Programming with ChatGPT
The study explores the quantitative and qualitative aspects of human-LLM interaction for software development, focusing on the use of ChatGPT. The goal is to understand the impact on code quality, productivity, and overall programming experience in an enterprise setting.
DEsign and Goals
It is a within-subject comparative study with 3 developers of varying experience levels. Participants completed 3 programming tasks of increasing complexity using only ChatGPT as a resource. Browsing documentation and asking peers was avoided. The tasks involved building a simple 3-tier website with login/authentication functionality. After each task, participants completed a survey on their experience. The goal was to assess ChatGPT's capabilities and areas for improvement to inform our own generative AI tools.
While an extensive research has been done on the quantitative benchmarks, very few have shared their opinions on the qualitative aspects. Yes the code is accurate but is it usable? And how easy is it to integrate the code into your humongous project? A few key questions that we focused on are : How did ChatGPT affect the programming experience? Was it able to maintain a coherent conversational flow? Were there any instances where ChatGPT provided irrelevant or inaccurate responses? Does ChatGPT show unintended biases or controversial responses? How did user identify errors in the code generated by ChatGPT and what was the coping mechanism used to rectify these errors?
Themes that emerged
- Nothing is a blank canvas anymore! ChatGPT accelerates initial progress and is able to assist in all the phases of the development lifecyle right from whiteboarding sessions to implementation. This profoundly increases the task solving effectiveness.
- Although it will not generate a novel idea, and security was not an implicit factor, prompting it the correct way, developers can understand security vulnerabilities and the possible mitigations while scaling mission critical applications where security can be a business differentiator.
- What is the margin of cost and error that we are willing to accept? The responses are a good fit statistically, given the prompt, without supervision or training of what the right response should be. Therefore the code generated had both semantic and syntactic errors which needed atleast a beginner level of coding experience to resolve. Further, when a part of a huge code block doesn’t work and since ChatGPT doesn’t always match our coding style, do we modify the code or rewrite it ourselves? A few times I found myself in time-consuming debugging rabbit holes.
- Prompting plays a huge role in eliciting a satisfactory response. But is the prompt reversible or irreversible? A question/prompt is considered reversible if we can discern from the response the nature of the source of the response (say AI or Human). For example, 2 + 2 is a irreversible prompt, but ethical and semantic questions can be reversible. LLMs struggle with reversible prompts.
conclusion
ChatGPT shows promise for transforming the software development process. However, through this study I observed that critical thinking and oversight remains essential to produce production-ready code. How far can we augment developers by decomposing complex programming challenges into discrete prompts tailored to an LLM's capabilities? Can LLMs as code generation tools possibly eliminate the need for syntactic sugar and language specific idioms? Can a pseudo language for prompting give us better results? While significant obstacles exist, this study opened up a path full of open questions and opportunities to expand an LLM’s utility for a seamless experience.
Further, evaluating different architectural styles and technical tradeoffs against ChatGPT's recommendations drove deeper reflection on how I approach system design. The back-and-forth with ChatGPT illuminated angles I hadn't fully considered before and pushed me to reconsider separation of concerns, maintainability, and reuse best practices

Bringing It All Together
My internship at Broadcom reaffirmed the importance of modernization as a multifaceted transformation encompassing technology, processes, and…..PEOPLE. It is a Cultural Transformation! After three years of work experience and a year in academia, this opportunity allowed me to reconnect with fundamentals, unlearn few perspectives from before, getting up to speed with the new-mainframe, explore the modern skills I learnt in academia and apply all of this in the current practical context. I'm grateful that Broadcom provided this encouraging environment.
In an open-door and amiable environment I had the chance to learn from incredible mentors and colleagues along the way. Hearing their unique stories and experiences only further motivated me to keep learning, push my abilities and change for the better. I'm thankful for the personal growth opportunities Broadcom provided through exposure to new technologies and ways of thinking. The lessons from this experience will stay with me as I continue pursuing my goals.
Works that I referred
- GPT-3 : Its Nature, Scope, Limits, and Consequences. Luciano Floridi, Massimo Chiriatti
- Expectation vs. Experience: Evaluating the Usability of Code Generation Tools Powered by Large Language Models. Priyan Vaithilingam, Tianyi Zhang, Elena L. Glassman
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, Denny Zhou
- SudoLang: A Powerful Pseudocode Programming Language for LLMs.