There’s lot of reference on HA but not so much on DR.
Need help on any reference that may be useful as a reference point design to have both HA and DR enabled.
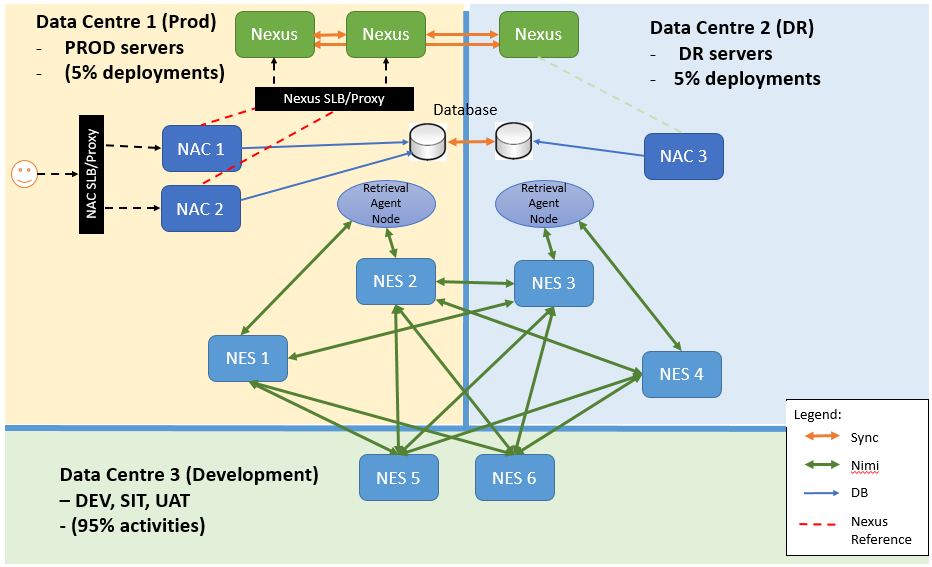
Below are a draft overview stack placement (after several iterations) on which one client is trying to pursue (note: all NAC are connected to each NES).
- Three data centre with strict firewall and limited bandwidth from each other
- Data centre 3 will have the most deployment activities (Dev, SIT, UAT)
- Database replication CANNOT be perform between DC3 and DC2. Thus below DB are in DC1 and replicated to DC2 for DR purpose.
- Some of the requirements:
- NAC1 and NAC2 shall complement each other for HA. NAC3 will be passive when DC1 is up and running.
- NAC3 shall kick in (with reasonable SLA turnaround) when RA servers in DC1 is down.
- Switch back to DC1 servers when infra is up and running
I am curious to know:
1) If the nexus HA will work on below setup during actual usage. Have we encountered any sort of glitches/performance issue due to sync delay/latency on nexus.
2) If it's redundant to have SLB/Proxy for NAC given the performance bottleneck for RA is actually at Database. Switching to another NAC would not necessary resolve load issue, right?