Team,
One of the challenge with a multi-cluster solution, is the location of log files are across individual nodes.
If there are no error messages or stuck "In-Progress" tasks, the administrator/user may use the IM View Submitted Tasks (VST) process to track the full data path from front-end components,e.g.
- CA Identity Portal via TEWS (SOAP web services),
- HR (Source-of-record) Feeds via custom ETL (extract-transform-load tools - powershell/PDI/kettle/java/other) via TEWS (SOAP web services),
- HR (Source-of-record) Feeds via TEWS (SOAP web services) via CA IM Bulk Loader Client (BLC tool)
Testing Tools:
- CA BlazeMeter (SaaS services; has built-in Jmeter capability in Chrome extension)
- SOAP UI via TEWS (SOAP web services) [Free or Paid tool]
- Jmeter UI via HTTP/S (emulate user interaction) or TEWS (SOAP web services) [Opensource tool]
However, if there are any error messages, and if the J2EE clusters are properly setup, then business logic will "bounce" between the J2EE nodes. Which make tracking errors and RCA (root-cause-analysis) challenging to identify the log entry that will provide value to address the issue.
Example: Stuck "In-Progress" IM tasks.
These appears to be related to data quality or PX math operations within the associated PX rules tied to the task name or event (create/mod/term).
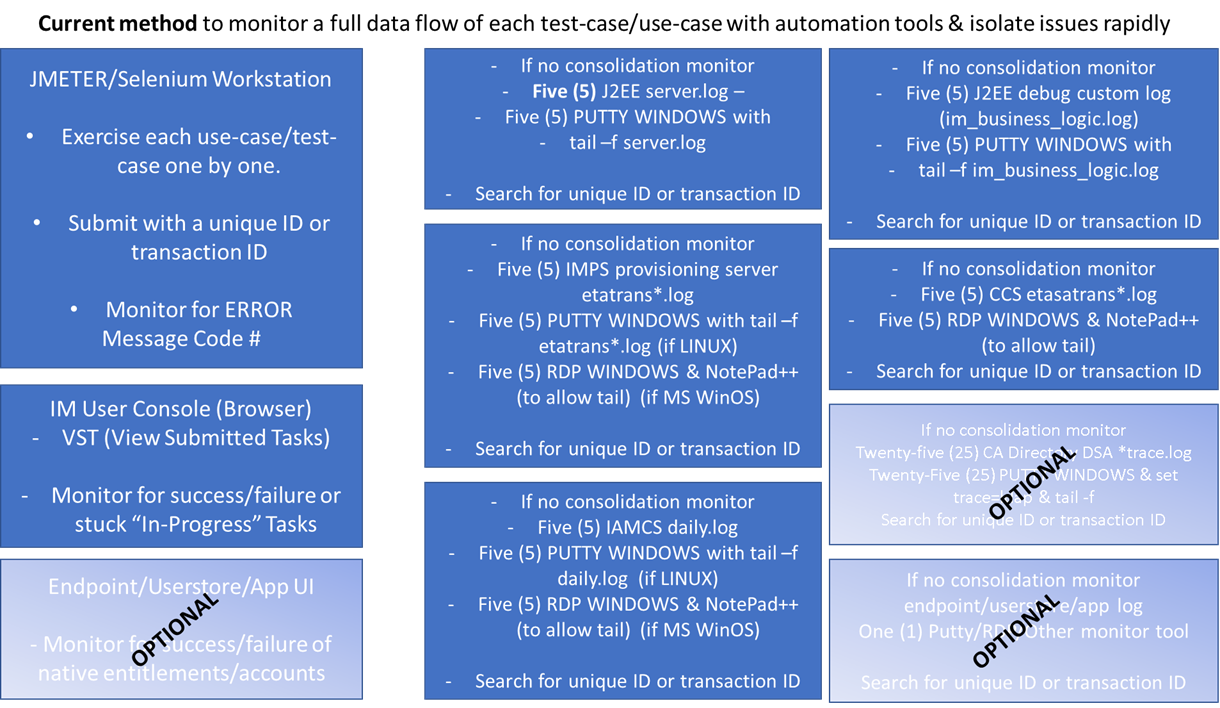
One view to help see the challenge, assume that we have five (5) nodes for each tier; and have automated all of our test cases with a testing tool (CA BLAZEMETER/Selenium/SOAP-UI/JMETER/other)
We would have this challenge, with no consolation of logs:
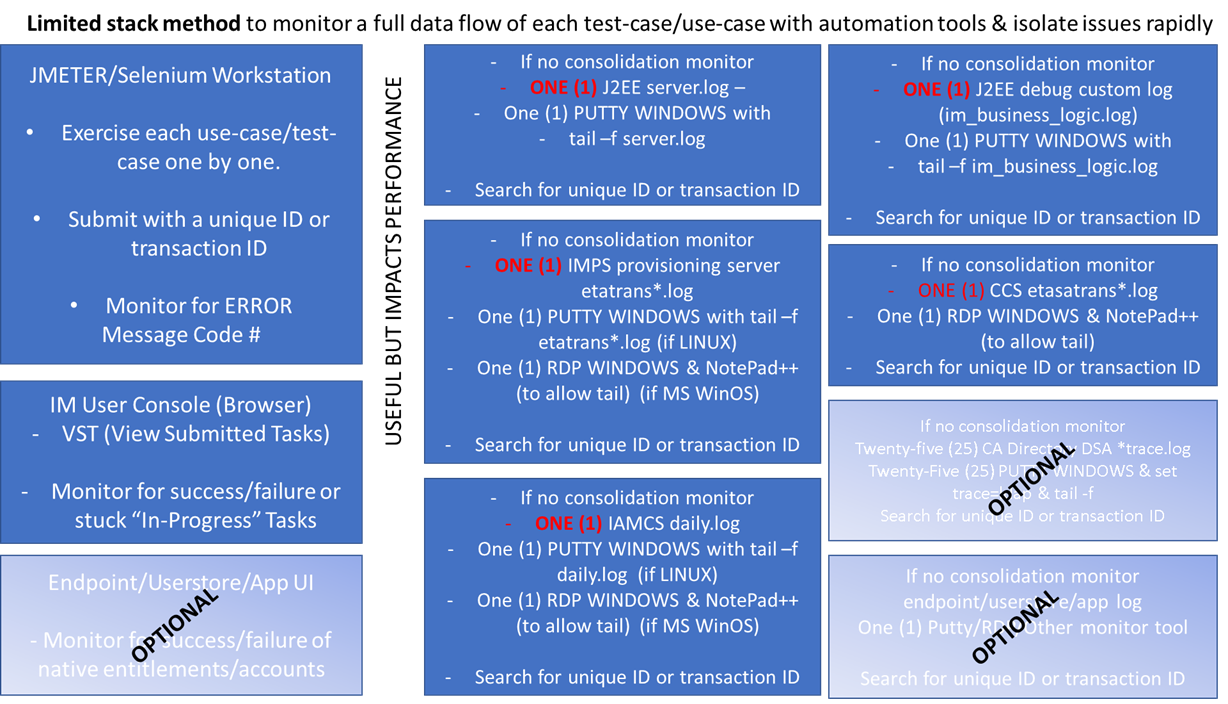
Alternatively, if we need to work in a production environment, with no consolidation, we could stop all nodes, except for ONE stack, but we would likely experience performance challenges for ongoing activity.
Best option, with some form of consolidation. Either a shared mount point or data collection solution.

What consolidation do you use?
Cheers,
Alan