Time to time we notice a critical chassis down alarm not clearing by itself. How do we troubleshoot to root cause? BGP reestablished few minutes later. It shows STALE but it should have cleared by itself.

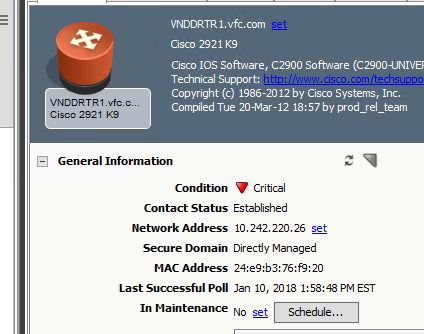
ITGC2W000145%/d/CA_Spectrum/vnmsh > show alarms -a mh=0x50e171
ID Date Time PCauseId MHandle MName MTypeName Severity LastOccurDate&Time Ack Stale Assignment Status
46955415 01/05/2018 02:12:41 0x10f71 0x50e171 VNDDRTR1.vfc.com Rtr_Cisco MAJOR 01/05/2018 02:12:41 No Yes 13845619 05/20/2017 15:28:40 0x1030a 0x50e171 VNDDRTR1.vfc.com Rtr_Cisco OK 01/06/2018 06:06:18 Yes Yes 46955413 01/05/2018 02:12:41 0x10f69 0x50e171 VNDDRTR1.vfc.com Rtr_Cisco CRITICAL 01/05/2018 02:12:41 No Yes ITGC2W000145%/d/CA_Spectrum/vnmsh > ./disconnect
Events Tab
Jan 5, 2018 2:14:30 AM EST VNDDRTR1.vfc.com "A ""cbgpFsmStateChange"" event has occurred, from Rtr_Cisco device, named VNDDRTR1.vfc.com.
The BGP cbgpFsmStateChange notification is generated
for every BGP FSM state change. The bgpPeerRemoteAddr
value is attached to the notification object ID.
bgpPeerLastError = 0.0
bgpPeerLastError.bgpPeerRemoteAddr = 10.255.28.29
bgpPeerState = established
cbgpPeerLastErrorTxt =
cbgpPeerPrevState = openconfirm"
Jan 5, 2018 2:14:30 AM EST VNDDRTR1.vfc.com A bgpEstablished trap has been received for this device. The peer router is 10.255.28.29, the current state is established, and the LastError is 0.0.
Jan 5, 2018 2:14:30 AM EST VNDDRTR1.vfc.com_Se0/0/0 The BGP Peering session from VNDDRTR1.vfc.com to US MPLS Sprint AS1803 is established.