I will add few things to list which are good to take a look, some you might already have them setup ...if not you can take a look
-Monitor only the once which needs to be monitored , do not start with everything
- Minimise the number of QoS metrics which you write to the database and try to make it a standard as much as possible using predefined templates across your environment. Try not to write any QoS to DB unless you need it for reporting or for any long term analysis .
- Always start small and add as you need it when it comes to the QoS or Alarms , not the other way round. It is never a good idea to enable everything and then start thinking ...do it really need it or not?
- Have control of the Alarms that you have enabled and the threshold which you have set, though it is recommended to use the monitoring templates ..you would come across scenarios where one size may not fit for all. In such a cases it is good to set thresholds manually based on the need, an example would be monitoring disks and setting a standard threshold in % where 5% threshold could be 10G or even 100G . Manually adjusting the thresholds based on the historical trend would be helpful in this case. This would bring down some false alerts which do not need our attention .
- Be careful when working with alerts which do not auto clear, like the ntevent alerts , logmon alerts or the server reboot alerts. If you have too many of these configured you would end up watching all these sitting in alarm console all the time.Try to have a AO rule set up to close the less critical or stagnant alarms at regular intervals
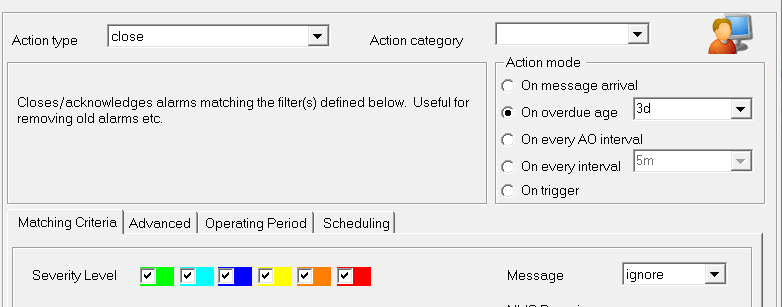
There are many other things we can follow to keep the system healthy and to reduce noise ..I will keep adding them to this list as it comes to my mind