Although best way is to avoid the loss of DLR Control VM with HA and Anti-Affinity mechanisms, if understood correctly the question is " what would happen to the routing tables on the DLR instances on ESXi hosts if b Both DLR VMs are down when OSPF is used?
If the Design is ECMP based for throughput increase instead of Active-Standby Edge which is single next-hop for DLR, then dynamic routing protocols are necessary.
The 2 default routes are inserted into the routing table of the DLR by the Edge through OSPF Routing Protocol, which is in turn distributed to the DLR Instances on the ESXi hosts. Since this is ECMP Scenario, different Flows may choose different next-hops pointing either to .2 or .3. Since there are 2 next-hops, not sure without testing 2 distinct static default routes with higher administrative distance would achieve a backup mechanism. (may not be recommended due to possibility of losing the next-hop edge which may create problem of losing half of the flows since there is no mechanism as ip sla of understanding the next-hop edge is lost ).
Worst case may be again configuring single static route for one the Edges, but this again Anti affinity rules are needed for minimizing the risk of losing the Control VM and this next-hop Edge at the same time. If the ESXi host is lost, even if the Edge would power on on another ESXi host through Vmware Vsphere HA Mechanism, it may be tested if this time is sufficient for Applications.
So for ECMP scenarios, best practices for increasing the Availability of DLR Control VM with HA(High Availability) and avoiding the possibility of losing Edge and Active Control VM at the same time would decrease OSPF failure to a very minimum, which may be sufficient for most of the cases. Affinity rule for DLR VM HA is defined automatically, but recommended seperation of Data Stores of the 2 DLR VMs with Storage DRS manually, because it is not automatic as of 6.2.
https://fojta.wordpress.com/tag/ecmp/
"The other consideration is placement of DLR Control VM. If it fails together with one of ECMP Provider Edges the ESXi host vmkernel routes are not updated until DLR Control VM functionality fails over to the passive instance and meanwhile route to the dead Provider Edge is black holing traffic. If we have enough hosts in the Edge Cluster we should deploy DLR Control VMs with anti-affinity to all ECMP Edges. Most likely we will not have enough hosts therefore we would deployed DLR Control VMs to one of the compute clusters. The VMs are very small (512 MB, 1 vCPU) therefore the cluster capacity impact is negligible"
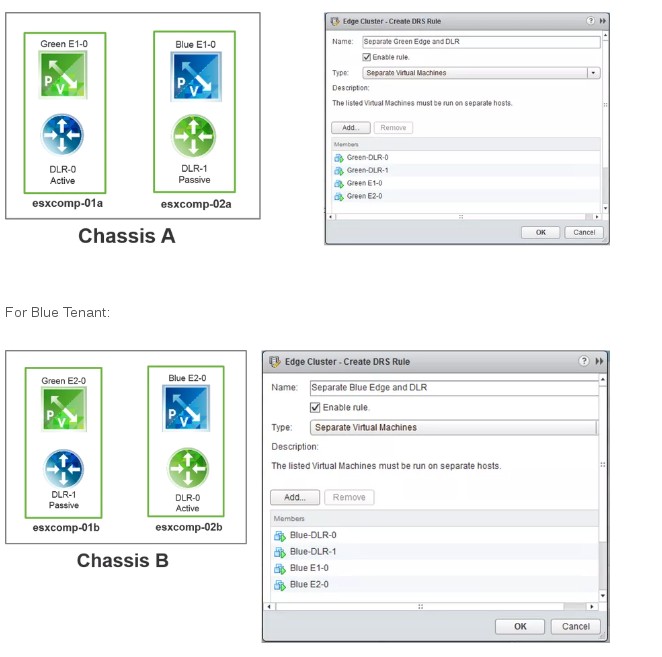
ESG Affinity Rules for SDRS
"The design guide speaks to some of this in table 10 of the 3.0 guide. ESG and DLR Control HA enables anti-affinity automatically but ECMP needs enabled manually."

http://www.routetocloud.com/2014/06/nsx-distributed-logical-router/#DLR_High_Availability
The High Availability (HA) DLR Control VM allows redundancy at the VM level. The HA mode is Active/Passive where the active DLR Control VM holds the IP address, and if the active DLR Control VM fails the passive DLR Control VM will take ownership of the IP address (flip event). The DLR route-instance and the interface of the LIFs and IP address exists on the ESXi host as a kernel module and are not part of this Active/passive mode flip event.
The Active DLR Control VM sync-forwarding table to secondary DLR Control VM, if the active fails, the forwarding table will continue to run on the secondary unit until the secondary DLR will renew the adjacency with the upper router.
http://www.routetocloud.com/2014/12/nsx-edge-and-drs-rules/
An Edge and DLR that belong to the same tenant should not run in the same ESXi host: