In large scale organizations, it is often necessary to move data from DB2 Production subsystems to Test subsystems. Of the various technologies that are available to achieve this business objective, circumstances determine which is most appropriate. Additionally, it is sometimes necessary to consider extra technologies such as Encryption or Masking to meet data security expectations.
Techniques available to move DB2 data across subsystems
A picture says a thousand words. The following analogy may help you to digest some concepts that are often difficult for non-DB2 experts. A DB2 subsystem can be represented as a library that stores books (DB2 Tables), and each book contains data. In DB2, each object has an internal identifier, an ID. Those are called OBID “Object ID”. For instance a Database has an ID, and a table has an ID. Think of a library where books have catalog numbers that are based on their location in the shelves. You can find a book in the shelves from its catalog number; similarly, you can locate a table in DB2 using a couple of IDs.

This concept is important to understand, because DB2 leverages those IDs to make sure that the data is where it belongs. If the IDs do not match, DB2 fails to retrieve the corresponding data. Additionally, it is almost impossible for a DB2 administrator to ensure that a DB2 Object in the Test subsystem has the same object IDs as in the DB2 Production subsystem. As highlighted in the above illustration, the green dictionary (circled in red) is in both the PROD library and the TEST library, but not in the same place on the shelves. That’s typically what PROD and TEST subsystems look like in a DB2 environment.
UNLOAD / LOAD
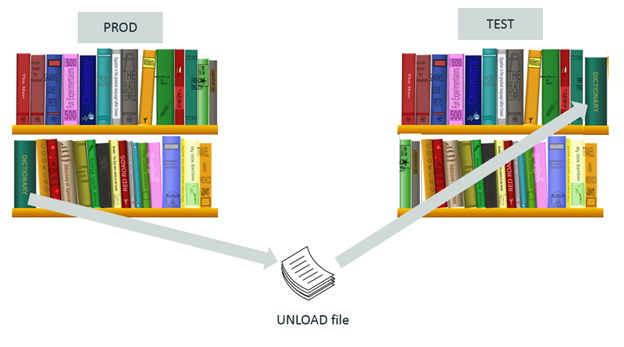
The most intuitive way of moving the data from a subsystem to another is by Unloading the data from the source subsystem (PROD), and Loading it back in the target subsystem (TEST).
However, in our library analogy, it’s a bit as if you read the book in PROD, used a typewriter to extract the content, and gave this manuscript to a publisher. The publisher then created a new book that you stored in your TEST library. Similarly in DB2, this UNLOAD / LOAD technique is quite inefficient, slow, and CPU intensive.
That said, this technique has some good benefits. It’s quite easy to put such a process in place (for instance, no need to care about the OBIDs), and it’s quite adaptive; it can handle some differences in schema and attributes of the tables (tablespace). In our library analogy, the publisher may have created a book in different format (pocket size or large booklet) for you to store in the TEST library, but you have no trouble recognizing it as the same book.
To implement this technique, use CA Fast Unload® for DB2 for z/OS (to create the Unload file), and then CA Fast Load® for DB2 for z/OS (to load the Unload file into TEST table).
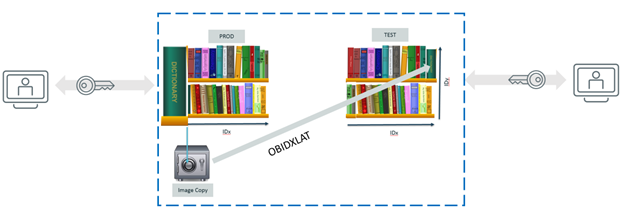
OBIDXLAT – leverage existing Image Copies

In your DB2 environment, you probably take Image Copies regularly to use in a Disaster Recovery scenario. In our library analogy, you may want to have a 2nd copy of your PROD book (an exact identical copy of the book) stored in a safe somewhere, so that if your PROD library burns down, you can replace it ASAP with the book in the safe.
Now, since you have an exact copy of the book in the safe, why not store it in your TEST library? Wait a second, that’s where the Object ID (OBID) comes into play: you cannot do that “so simply” in DB2, because those IDs will not correspond. However, you can use OBIDXLAT processing (understand OBID translation), to create the book in TEST with appropriate IDs.
This technique is much faster than the UNLOAD / LOAD technique described previously because:
- - You avoid the time and CPU required to “Unload” the data; you simply re-use the Image Copy that you already have in your PROD subsystem in case of disaster
- - “Loading” the data is also much faster, since this is not a load, but a recover process. In other words, the book is already an exact same copy of what you want in TEST, you just need to change a few IDs. It’s nothing compared to asking a publisher to create a book for you, based on a note made on a typewriter!
Here is the caveat: the DB2 table schema and the tablespace attributes must be identical for this technique to work. You cannot go to your safe and take a book in booklet format, and magically transform it into a pocketbook to store in your TEST library. That means, for the OBIDXLAT technique to work over time, any schema or attribute changes that are done on the table in your DB2 Production subsystem must be applied as well to the corresponding table in your DB2 Test subsystem.
This technique can be implemented by using CA Quick Copy for DB2 for z/OS (to create the Image Copy in the safe) and CA Fast Recover™ for DB2 for z/OS (to perform the OBIDXLAT processing, and Rebuild index on TEST subsystem if required). Additionally, if required, CA Fast Recover™ for DB2 for z/OS is also able to perform log-apply to the target subsystem replicate the updates from the source since the last Image Copy.
RC/MERGER – “just” take a Copy
Using RC/Merger processing, you can move data from your DB2 Production subsystem to your DB2 Test subsystem just by running a Copy. This technique is protected by a patent in the USPTO. Simply said, RC/Merger coordinates IDs across PROD and TEST, and takes care of differences in the DB2 table schema and tablespace attributes.
In our library analogy, RC/Merger acts as your personal librarian, insuring that all the books in the TEST library are in the same position (IDs) and format/size (Schema, attributes) as the books in the PROD library.
Then moving data is a piece of cake. You can run a Copy program to create an Image Copy that you store right away in your TEST library. In DB2 terms, you simply need to make sure the copy is created using the VSAM naming convention for the underlying DB2 TEST tablespace.
This technique can be implemented by using CA RC/Migrator™ for DB2 for z/OS (that contains the RC/Merger feature), CA Quick Copy for DB2 for z/OS (to create the Image Copy) and CA Fast Recover™ for DB2 for z/OS (to perform Rebuild index on TEST subsystem if required).
REDO processing to move DATA from PROD to TEST

When your data is “loaded” into the DB2 TEST subsystem, consider updating it on regular basis so the data is synchronized with PROD. You can perform this synchronization by using a Log Analysis tool. Such a tool reads the DB2 log and extracts the SQL DML activity (INSERT, UPDATE, DELETE, MERGE) that happened on the PROD table (in a given timeframe). The tool then plays the DML activity back on the TEST table (in other words, it executes those SQL statements against the TEST table to apply the same changes).
In our library analogy, if an editor came to annotate your green dictionary in PROD, to add a new word and its definition for instance, this REDO process would force him/her to go to the TEST library and make the same annotation there as well.
This technique can be implemented by using CA Log Analyzer™ for DB2 for z/OS (that contains the REDO processing feature).
Masking considerations

Data Masking is an option if the business data is highly sensitive and must not be visible to employees who have access to the TEST environment. However, those employees typically include QA engineers (testers) who require the masked data to be good quality, in order to create their tests efficiently using QA Automation techniques.
Some considerations about masked data quality include:
- Appropriate data format: For example, if a column, in a DB2 table, contains credit card number information, the Masking algorithm should produce masked data in a similar format (eg. respecting the Luhn algorithm) for the tests to work correctly.
- Respect DB2 RI: In relational databases, such as DB2, tables are connected using RI techniques (Relational Integrity). The Masking algorithm has to respect those RIs, even when the RI keys require masking in case they contain sensitive information.
- Persistent Masked data: QA engineers use this data to create automated tests in the TEST environment. If a column contains the customer’s names, one row may correspond to “John Doe”. If “John Doe” is masked by “Mickey Mouse”, the “Mickey Mouse” mask may need to be persistent for QA Automation purpose. In other words, employees who have access to the TEST system shall not know who “Mickey Mouse” is in reality, but “Mickey Mouse” represents the same person every time the TEST environment is loaded (and masked).
- Other business-related considerations: The masked data may need to follow certain rules, specific to a certain business. For example, financial institutions will have balance sheet tables that need to match across DB2 Tables given a certain timeframe (in other words, the balance shall be 0). The same applies to any data against which a checksum is performed.
Achieving the goal of good data masking, while maintaining the quality of the data for testing purposes is a challenge. CA Technologies offers several solutions to help with those challenges, such as:
Encryption considerations
Large corporations may be required to encrypt their DB2 business data, as it typically contains very sensitive information (PI, PHI, …). To access the data, users need the proper key:
Several encryption techniques exist on the market, and users may implement their own. To take an example, IBM Guardium allows Encryption using EDITPROCs (containing the encryption algorithm) and an Encryption Key.
Consider the impact of your encryption methods, when trying to implement a mechanism to move data from one system to another.
If you are thinking about using the UNLOAD / LOAD technique, you should not have any technical issues. However, you need to be aware that the Unload File will contain unencrypted data (outside of the control of DB2), which may defeat the purpose of trying to encrypt your data in DB2!
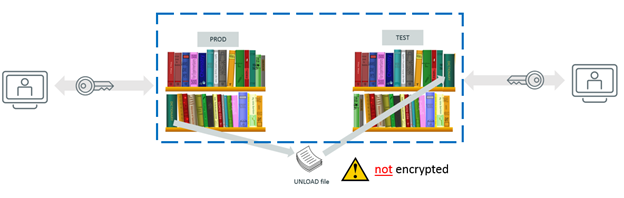
If you are thinking about OBIDXLAT (or RC/Merger) technique, data security concerns are much reduced, but you need to keep in mind that the EDITPROCs and Encryption Keys must match between the DB2 Production subsystem and the DB2 Test subsystem (since you are using an exact copy of the (encrypted) book in PROD, you are just creating the same book in TEST – with the same encrypted data content, hence you need the same Encryption Key on the TEST subsystem to read this book correctly).
A (small but important) note on Encryption: While DB2 encryption tools encrypt the data stored in DB2 tables, any key referenced by an index will be stored as unencrypted in the index (in other words your indexes will contain unencrypted data even if you activated the encryption on the related table). This helps SQL performance, as it avoids double-decryption for any SQL statement that uses an Index to access the data.
Although CA Technologies does not offer DB2 encryption product, we support customers using third party encryption software with our DB2 solutions for z/OS.