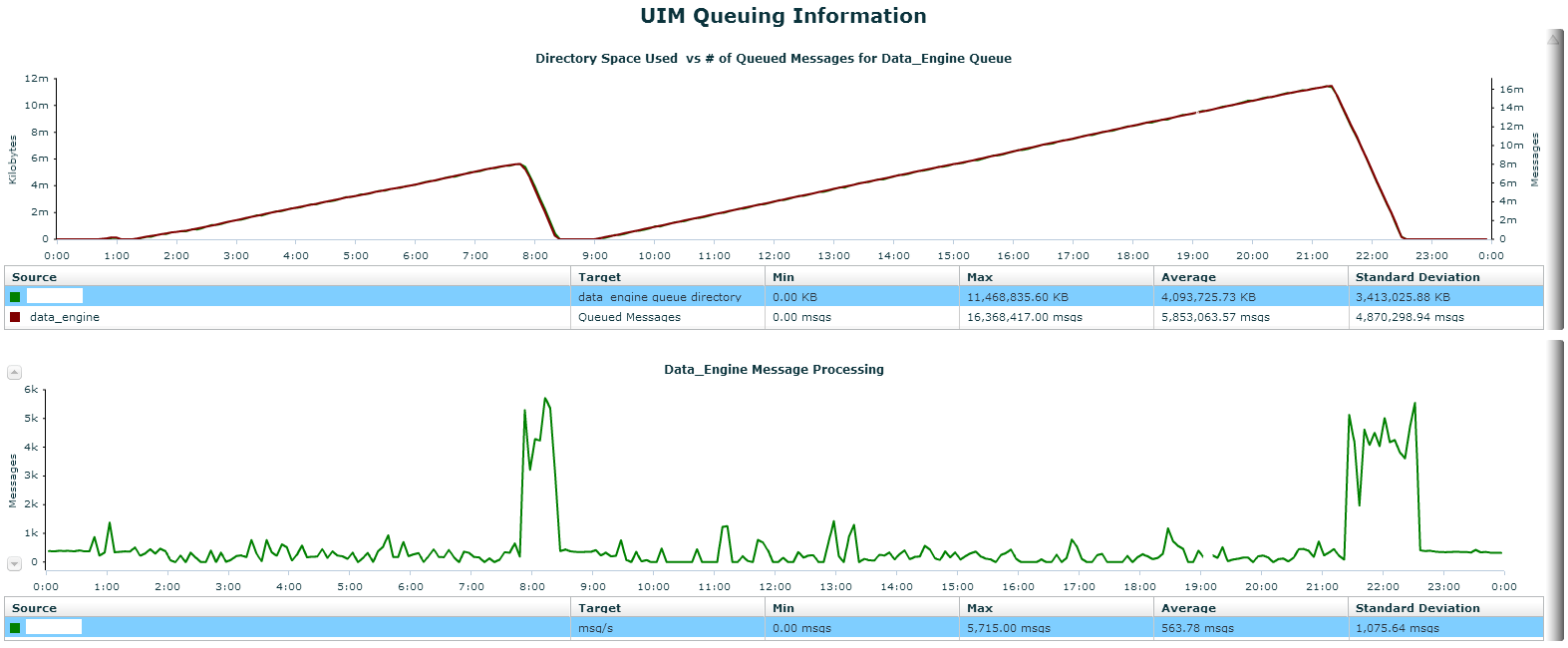
Has anyone experienced QoS queuing during re-indexing maintenance jobs? Our installation is large enough that CA recommends we don't enable "Index Maintenance" in the data engine probe. They recommend we do it directly in SQL enterprise edition. How is everyone else handling their re-indexing process?
Please respond with robot count, db size, and method if you can. Thanks!
We tried switching our back-end job to run weekly starting at 1am. This caused the job to take 19+ hours to run and you can see the effect it had on our QoS writing.