Introduction
In this blog post, a single endpoint of the HSBC Branch Locator API will be modelled[1] using Agile Requirements Designer (ARD), a market leading Model Based Testing (MBT) tool. This will allow us to increase the coverage of testing on this API. This API takes in 3 data parameters: latitude and longitude co-ordinates in degrees, and a radius in miles. It returns branch locations and details that exist within the specified radius from the given co-ordinates. The API has the following rules:
- The longitude and latitude must be United Kingdom (UK) based
- The radius can be between 1-10 miles
- The radius must be integer valued.
The API uses the ReST protocol and supports Get requests. It can be queried using the following URL:
https://api.hsbc.com/x-open-banking/v1.2/branches/geo-location/lat/{latitude}/long/{longitude}?radius={radius}
For instance, the latitude and longitude of CA Technologies UK office, Ditton Park, are {51.4914, -0.5602} degrees. Therefore if we want to find all the HSBC branches within a mile radius of this office, we send a Get request to this URL:
https://api.hsbc.com/x-open-banking/v1.2/branches/geo-location/lat/51.4914/long/-0.5602?radius=2
A portion of the returned JSON is shown in Figure 1.
Figure 1: The JSON returned by https://api.hsbc.com/x-open-banking/v1.2/branches/geo-location/lat/51.4914/long/-0.5602?radius=10
As a tester, we want to create a number of valid and invalid URLs to query this endpoint. Then based on the response we can understand if the API is handling the request in the correct way. To do this we must model the data permutations for the endpoint. The documentation[1] defines the following expected results:
- Valid URL : HTTP Status code 200
- Invalid URL (incorrect input) : HTTP Status code 400
Alternative things to test
The Simplicity of this API means there are not many different examples of testing we could do with it. But, some APIs output a call to another API, in many cases these may form part of a sequence to execute some business process. For instance HSBC could develop an API that combines calls from the Branch Locator API with the HSBC ATM Locator API[1]. (The ATM locator API works in a similar way to the Branch Locator except it finds ATMs.) This would allow us to find Branches, with a specified number of ATMs at a particular-location. We could compare the data returned with independent data which lists the number of ATMS near a given branch. This data could come from Google Maps. This tests if the sequencing of the calls is correct.
Creating the Model.
Since the ARD model will model the data combinations for querying the API we now consider the data. The rules stated in the Introduction bound the data. The Latitude and Longitude must exist within the UK, this means that we must have a Latitude from 50.10319 to 60.15456 and longitude from -7.64133 to 1.75159[3]. Similarly the Radius must be between 1-10 miles and take integer values. This gives us bounds for our data, but in the case of latitude and longitude, we could still select an infinite number of values within the bounds. So for brevity we choose 3 kinds of values: Valid, Invalid and no value/Empty. Valid values are of type float and exist within the range, invalid values are of type float and do not exist within the range. We assume these ranges are ‘Equivalence-Partitions’[4; pg120] . This means that we hope that values within this range are ‘equivalent’ in terms of their ability to detect failures [4; pg132]. Therefore we need only test one value within each range and these are shown in Table 1. We could also consider invalid longitude/latitude values such as “46.0fdf5”, i.e. an alphanumeric value or non-integer radii within the valid range. In the interests of reducing the number of test cases and avoiding “Test-Case Explosion” [4; pg17] we neglect such values.
|
Data
|
Valid Equivalence Partition
|
Invalid Equivalence Partition
|
|
Latitude/degrees
|
50.10319 to 60.15456
|
> 60.15456 or < 50.10319
|
|
Longitude/degrees
|
-7.64133 to 1.75159
|
> 1.75159 or < -7.64133
|
|
Radius/miles
|
1 to 10
|
>10 and 0-1
|
Table 1: Values chosen for valid and invalid data.
The model is shown in Figure 2
Figure 2: The ARD Model used to generate URLs for the HSBC Branch Locator. A model is formed from ‘nodes’ or blocks and the connections between the block ‘edges’. The blocks are numbered 1-10 for reference. A path is defined as the route traversed from the Start (block 1) to the End (blocks 6 and 7) blocks.
A best practice when building models is to begin with a so-called positive test case, or in the MBT world, a ‘happy path’[4;pg208]. This path contains the following edges: Valid UK Latitude->Valid UK Longitude->Radius = 1-10 miles at blocks 2, 3, and 4 respectively. This means that only one path out of the total results in a valid request being created. The remaining logic is implemented for the negative test cases. This is justified as for Model Based Testing, and testing in general, most test cases should be negative. Blocks 10 and 9 are respective ‘clones’ of 3 and 4. A clone is an ARD specific term and it means that the blocks are identical to one another, same name, same attributes. Any change to the original is mirrored as a change to its clone. The reason we create these clones is because we know that all paths that traverse either one of these blocks create invalid requests. Therefore they will pass through block 8 as opposed to block 5.
An interesting point to note is that for the radius data we have edges for two invalid equivalence partitions 0-1 and >10. In the case of longitude and latitude we have only one. This will result in more testing of the radius parameter and this is justified because radius has 2 requirements associated with it. Therefore we should test each requirement separately.
Using Test Data Variables.
The flow in Figure 2 gives us a way of visualizing different data combinations for the API but it doesn’t create any URLs. To do this we must parameterize the logic using the ARD Test Data attribute, which can be configured for edges on blocks. If we double click Block 1 – Enter Base URL and open this page, we are presented with Figure 3a. This shows how we use a variable BaseURL to create the common prefix found in all Get Requests in the model.
Figure 3a: The Test Data pane for Block 1 on Figure 1. This shows the test data variables configured for Block 1. Any path which traverses this block will have its BaseURL variable set to the value shown on the right hand side of the equals.
Figure 3b shows the Test Data pane for block 2 – choose latitude. The test data variable values for blocks 3 and 4 (and their clones) are not shown but they are set in the same way.
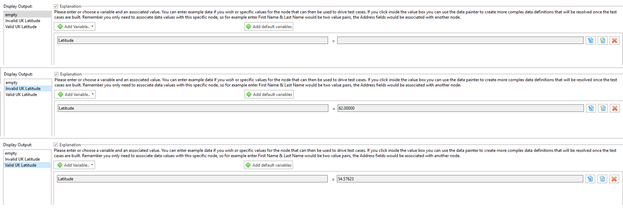
Figure 3b: The Test Data pane for all out edges of Block 2 on Figure 2. This shows the test data variables configured for Block 2. There are three edges that leave block 2, and so we have three values for the Latitude test data variable, one for each edge. In this instance we have chosen constant literal values consistent with the ranges defined in Table 1. (As an alternative we could use ‘datapainter[2]’ which integrates ARD with TDM functionality that could generate random values within these ranges.)
Figure 3c shows the Test Data Panes for Blocks 5 and 8. These blocks dictate the results of each test case
Figure 3c: The Test Data pane for blocks 5 and 8 on Figure 2
Generating the Paths
In order to generate the paths for our system we click Manage->Path Explorer. In this instance, we are going to choose all possible paths and create a stored path type named ‘Exhaustive Paths’ which in effect is all different data combinations/permutations for the model. Doing so produces 36 so called ‘Exhaustive Paths’ and Figure 4 shows the path explorer window after generating 36 paths.
Figure 4: Path Explorer window when all possible paths are generated for the model shown in Figure 2. The path shown is the single positive test case.
Exporting the Test Data
The RequestURL is defined by the Test Data we set in the preceding logic. A powerful way to visualize the values taken by this variable is to use the test data screen in Test Factory and this is shown in Figure 5. Each row represents a path in the flow and the column headers are defined by the test data variables in the flow in addition to three default columns that appear with every flow: flow_name, test_name, expected_results.
Figure 5: The Test Data summary screen found in TestFactory Ribbon->TestData. This is showing the ‘Resolved Test Data’, this page is shown after clicking resolve on the ‘Unresolved Test Data’ ribbon.
From this screen we can export the test data to a CSV file or to the GTREP repository. This is incredibly useful as it could be used by test automation engineers in a data driven testing framework. If the rules or requirements of the API change, or they were not described correctly in the first place, then we can adjust the model and then it’s just two clicks to export the new dataset. The point this illustrates is that Test Design, including Model-Based Test Design, is very much an iterative process[4;pg114] and so the ability to react to change quickly and correctly cannot be understated. A tool like ARD aids the tester tremendously in these kinds of tasks.
EXTRA - Adding Automation to perform an automated test.
ARD is used to generate and manage test assets effectively (like in the previous example where we created get request urls), however it cannot execute automated tests natively. What ARD can do is generate the scripts for these tests in a way that allows them to be maintained more effectively than traditional 'manual' methods. The scripts can then be executed in the testing framework of choice of the user.
The following example will use node-js to send requests to APIs and compare the http response code with what is expected. To replicate this example there are two prerequisites:
- Node JS downloaded and installed.
- The xmlhttprequest nodeJS module installed (use cmd npm install xmlhttprequest).
The best practice for generating these scripts is to use the flow previously generated as a subflow inside a parent flow named the ‘HSBC API Branch Locator Master’. The parent flow is shown in Figure 6. Since the child flow has two terminations, we must have two out-edges from this block. These edges meet at block 12 – Construct Variables for script.
Figure 6: The HSBC API Branch locator Master flow. The orange hexagonal block contains the subflow shown in Figure 2.
Double clicking on Block 12 and navigating to the Test Data pane reveals Figure 7
Figure 7: The Test Data pane for block 12 in Figure 6.
Here we can see how we get the value of ‘RequestURL’ from the HSBCAPIBranchLocator subflow using the scope resolution operator :: and referencing the subflow by name. The same method is used to set the ‘ExpectedHTTPStatus’ variable.
Setting up the Automation Script
To create automated test scripts in ARD we attach automation 'code snippets' to each block. When we export a single path we are exporting a concatenation of all the snippets attached to the blocks in the path. Then we can choose to export a merged script, this concatenates the scripts for each path into a single script.
To begin we open the automation configuration by clicking on the Automation tab on the home page. The configuration is shown in Figure 8
Figure 8: Automation configuration required to create automated node-js tests for the HSBC Branch Locator API. In ARD we have the concept of automation objects and actions. Conceptually an object is some item that has some number of actions associated with it and the actions like methods that do something relating to the object. The developers reading this will notice the idea is similar to that of Object Oriented Programming.
We see in Figure 8 that we have two actions for our script. These are: FunctionDefinitions and SendHTTPRequest. Function Definitions contains code to define the functionality required to send the HTTPRequest, and SendHTTPRequest is code for the invocation of the function.
At this point we have the automation defined but we have not inserted it into the flow. To add the SendHTTPRequest snippet, we exit the dialogue, double click block 13 on Figure 6, and navigate to the automation pane. This is shown in Figure 9.
Figure 9: The Automation Snippet that has been added to block 13 in Figure 6. The strings surrounded by tildes are replaced with the Test Data variables we created in Block 12 and shown in Figure 7.
At export this means that any path that passes through block 13 will now have this code added. Our system generates 36 paths, so for a merged script this will be generated 36 times, or we will send 36 requests. This makes sense.
All that is left is to insert the ‘FunctionDefinitions’ action. We should not attach it to a block like for SENDHTTPRequest. If we did and exported all paths in a single script it would appear 36 times in the merged script. Since we need only define the functions once (as per the rules of node-js) we define a ‘Flow Header’ parameter which appears as a header, once per merged script. This is set in the Export pane of figure 8.
Exporting the Automation Script
Now the automation is set up, all that is left is to export the script. To do this we click Test Factory -> Export Automation and we configure it as shown in Figure 10, choosing merged scripts and naming the file with the suffix .js.
Figure 10: The automation export screen used for the export of node-js automated tests for HSBC Branch Locator API.
Executing the Automation Script
To execute the test script, open a command line window in the directory where the file _HSBCBranchLocatorAPITestScript.js is located. After this we execute with the following syntax “node _HSBCBranchLocatorAPITestScript.js”. A file called TestCaseResults.txt is then created with the following structure:
Figure 11: The automation export screen used for the export of node-js automated tests for HSBC Branch Locator API. Note that the ordering of your results may not look like this since the printing of results to the text file is asynchronous.
Analysis of the results of the Automation Script
The first observation that can be made on this diagram is that several tests were returning 200 status codes when in our model we dictated that only one should, the happy path. The documentation defines this status code to mean that the request was understood.[1] If we dive deeper and query the 7th row URL in Figure 11 (https://api.hsbc.com/x-open-banking/v1.2/branches/geo-location/lat/54.57623/long/-1.23483?radius=) this returns the JSON shown in Figure 12:
Figure 12: The JSON returned when we query this https://api.hsbc.com/x-open-banking/v1.2/branches/geo-location/lat/54.57623/long/-1.23483?radius=
This is probably a bug, how can Branches exist within a radius= no value.
Another interesting observation is that some URLs are returning HTTP 403 errors when these are not listed in the documentation for the API. A quick Google search reveals that typically 403 errors are forbidden requests, where “the server can be reached and process the request but refuses to take any further action. “[5] This is either lack of documentation or a bug with the API.
The relatively simple analysis we have performed here has probably uncovered bugs and API documentation errors. Now, armed with this visual model, a tester can have a much more precise discussion with the API developers about the origin of these bugs. This contrasts with describing the system and bugs textually. This is the power of Agile Requirements designer and MBT and why you buy Agile Requirements Designer today!.
Find out more at: https://www.broadcom.com/products/software/continuous-testing/agile-requirements-designer
References
[1] HSBC, API Branch Locator Available from: https://developer.hsbc.com/swagger-index.html#!/Branches/get_x_open_banking_v1_2_branches_geo_location_lat_latitude_long_longitude
[Accessed - 03 January 2018].
[2] CA Technologies, Agile Requirements Designer Managing Test Data - DataPainter. Available from: https://docops.ca.com/ca-agile-requirements-designer/2-6/en/managing-test-data
[Accessed - 03 January 2018].
[3] Uk lat and long http://latitudelongitude.org/gb/
[Accessed - 03 January 2018].
[4] Kramer, A., 2016. Model-Based Testing Essentials - Guide to the ISTQB Certified Model-Based Tester. John Wiley & Sons.
[5] HTTP 403 https://en.wikipedia.org/wiki/HTTP_403