Note: I'm posting this document now. I've been trying to finish it for some time, but keep getting caught up in other more urgent tasks - I've put in an effort to get it to this stage - and will fix up any problems as I find them - Cheers Mark
1. Introduction
About 9 months ago, as part of API Gateway performance issue, I partially modified a program we have been using fairly effectively in CA SSO to read API Gateway ssg_X_X.log logs. The program Siteminder Policy Trace Analysis ,works on trace logging logs, and identifies: transactions, transitions within the transactions and worker threads. It then generates a pdf report that can be used to give some insight into where the threads are spending time - and hopefully some clues to where bottelnecks are - this seems to work particualrly well for analyzing logs and identifying performance bottlenecks of systems that are in trouble.
Recently, as part of another performance issue, I made some improvements in the ssg log support for the SMPolicyTraceTool's. It's not complete, and is still a work in progress, but even in its basic form it's useful - so thought it good to post an update on how it works with ssg log files and how to run it here.
Why yet another tool? - good question - there are some good tools for ssg log file analysis, this tool does repeat some of that found in dashboard and in APM for API Gateway - but has a few unique plots that help pinpoint bottlenecks. It does rely on enabling trace logging however , usually whenever there is a problem.
2. Process Overview
The process is :
- We enable some global policy to trace when messages and services are started and completed.
- Then enable (specific) trace logging for the services we want to dig into.
- Capture the ssg_X_X.log from the gateway.
- Run the SMPolicyTraceTool over the logs. It parses them, identifies threads & transactions and builds a pdf report file and sub-directory of transactions that took longer than the cutoff time.
3. Results Overview
The pdf report is broken into sections. The first is "ProcessRequest" which is summary for all services, then there is section for each Service, and finally some summary graphs and any long transactions (up to a limit).
These results are for a simple load test using jmeter, and are calls to a service /testTrace/* that delegates to three other services on the same gateway. The jmeter setup has 800 threads that loop for 100 times, and ramp up over 5sec. giving 78,666 calls that occur over about 13min.
Note: reviewing the screenshots however, I'd dropped off some of the training logs, and so the analysis here is only on about 3min of the trace.
The pdf index view gives the best overview of the report sections, visible here ProcessRequest, ServiceRequest. Within each major sections are the different analysis

The pdf report generated the following chapters in the pdf report for our load test :
1. Transaction Report : ProcessRequest - a total of all transactions
2. Transaction Report : ServiceRequest - total all service requests - can ignore this one for now)
3. Transaction Report : ServiceRequest /testTime1 - test case1
4. Transaction Report : ServiceRequest /testTrace/* - main entry point for load test - it then delegatest to /testTime1 /testxml1 or /testHash
5. Transaction Report : ServiceRequest /testxml1 - test case2
6. Transaction Report : ServiceRequest /testHash - test case3
The minor sub chapter headings in the report, give all the different graphs/tables - so are generated for each service and one (ProcessRequest) as a summary of all requests.
In the following sections of this document, in sections 3.1 and 3.2 I explain the more "interesting" graphs - but also maybe the more difficult to understand. And then in the sections after that, sections 3.3 and 3.4 , I describe the more "normal" graphs.
3.1 Results - SrcLine Thread State Transition summary times
For this part of the analysis, for it to make sense, I am looking at the load test main entry point "4. ServiceRequest /testTrace/*" which is the analysis of requests just to the /testTrace/* service. The /testTrace/* API pis fairly simple, depending on parameter it makes a "Route via HTTP" call to another service on this same
This service (as each service does) has it's own section, giving summary of requests av time, and distribution of response times etc:

But what we want to highlight here is how (with trace logging enabled) we can give a summary of the policy state transition within the service.
3.1.1 Service Policy State Transition Times Summary
Section X.4 SrcLine Graph plots a bar graph summary of all the policy transitions observed in the trace log and the summary of the amount of time (over all threads) that was spent time in each of those transitions.

So we can see above that transition from policy # 6 -> 24 was definitely the transition where most of the threads processing service /testTrace/* spent most of their time. This one is pretty obvious, but if you look at the attached pdf reports in this article, you can see different distributions.
While the graph is good to get clear picture of where most time was spent - we also have that in table format as well.
3.1.2 SrcLine Table
Here is the table entry for the above transition where most time was spent :

So over all threads processing this service, the total time spend doing this transition from 6 -> 24 was : 27,483 sec. or 458 min, or 7.6 hr
We can see this transition was called 16,097 Times with an av response time : 1,707.343 ms and response range of (min: 4 ms, max: 23,286 ms), (it is the small print last line in table - I'll improve the format for ssg logs in some release).
The table also as a sample give the details of the first transition 6->24 transition that it found in the trace logs. - these are a bit messy, since there is a lot of details in each trace line - I'll improve the format for ssg logs in some release.
Sample Transition :
From 6: At least one assertion must evaluate to true: Policy for service #310dd77d8f358c8e96f732c717b0193c,
testTrace - TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service
#310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97
assertion.numberStr=6 assertion.shortname=At least one assertion must evaluate to true
assertion.start=1541331482727 assertion.latency=18 status=0
To 24: Route via HTTP(S): Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace - TRACE:
service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service
#310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97
assertion.numberStr=24 assertion.shortname=Route via HTTP(S) assertion.start=1541331482746
assertion.latency=103 status=0
This service /testTrace/* is pretty clear. The service main bottleneck is waiting for a result from delegated HTTP request. If you look at the attached pdf report you can see different distributions for the other delegated services.
But even for a simple case like the wait for delegated HTTP that can be very important to know. For example if handling 100 req/sec and the backend takes 100ms to respond, then you need (100 x 0.1ms) = 10 active threads. But if the backend response slows to 1sec, then you need 100 active threads, and if the backend slows to 10sec then you will have 1,000 active threads for that service. Your idle timeout will generally determine the max size you thread pool for that service will grow to.
3.2 Results - LockDetect
Complementing the SrcFile graph above we generate a graph of how many threads are in the same state at the same time. This can often make it clear that say, there are 20 threads in one state (maybe with a db handle and doing activity) and 80 threads in a "wait" state waiting to get a db handle for instance.
The graph looks like this :
Results - LockDetect

Again this one fairly clear, in processing /testTrace/* most of the threads spend their time waiting for the delegated HTTP request to return. So they are in state "6" waiting for response from the delegated http server that will take them into state "24".
This graph is good at detecting which resource is causing a bottleneck, often that could be some lock or limited resource. There is also a table with details for each of the "LockDetect" states graphed. but not shown here. And there is a graph of throughput ie, how many times per sec the specific "LockDetect" state is passed through (also not shown) that can be useful.
3.3 Results - Simple Results
3.3.1 Summary
The overall ProcessRequest results here show we got 32,249 requests in the 2min 33sec, and gives throughput and av transaction times.

3.3.2 Distribution of Response Times
However average transaction times often don't tell the full story. Section X.2 graphs the transaction times - often many requests are very quick and then there are a clusters of slower ones - the graph gives a better feel for response than just an average time.
Note: the scale off the X axis has a kind of exponential quality to the range, so that responses over ms, and sec and min can be shown together and still make sense visually.
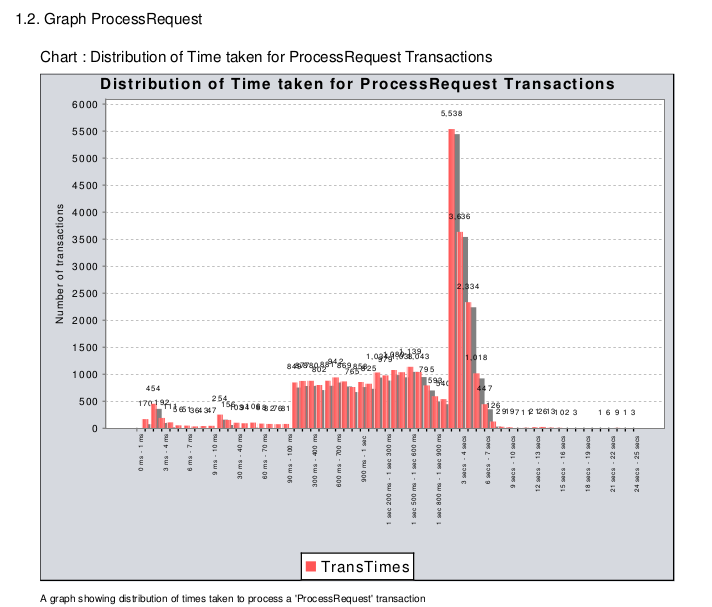
So above we can see that most transactions finished within 10 sec, but there are some that took as long as 25sec to complete.
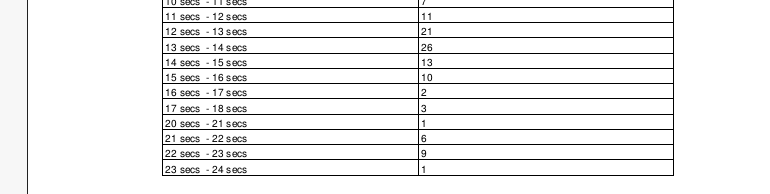
The graph results are also given in table form in the pdf report :
3.3.3 Concurrent Requests (Threads)
Section X.9 Shows the number of active threads
(I would change "Concurrent" name to something more meaningful, but it's embedded into a few places now).
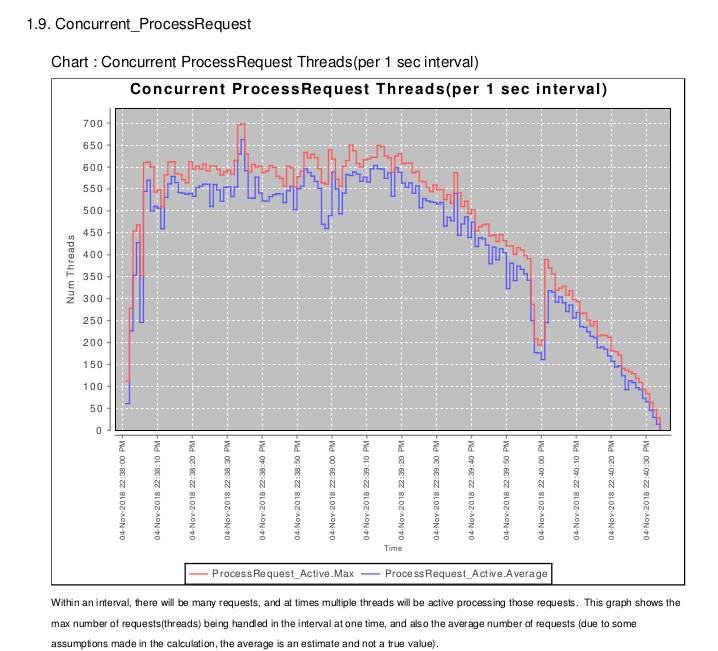
So we can see max of 700 threads/transactions active at one time, that we hit peak at 22:38:25 and that the load slowly trails off after 22:39:30
3.3.4 StartAndEndProcess
Section X.10 keeps a count of the number of requests started (red) and completed (blue) for each second.
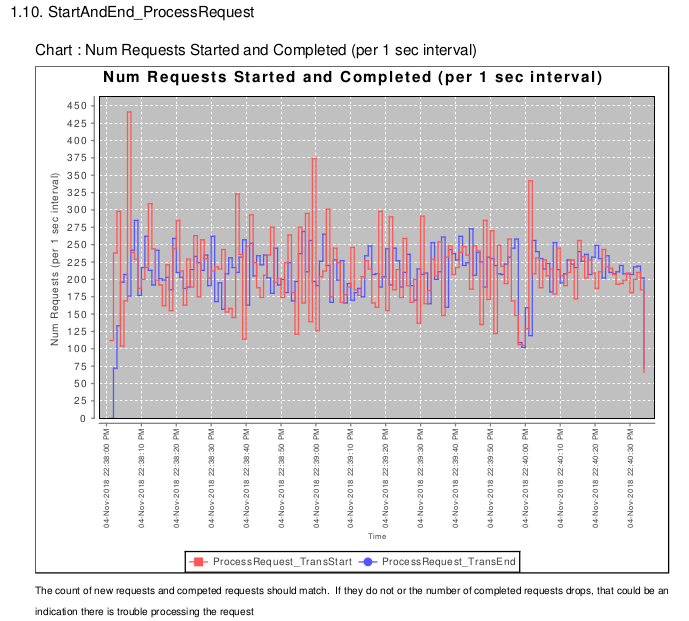
We can see if there is an imbalance, say where new requests come in at faster response than the API Gateway can complete them (that usually results in maxing out the number of worker threads).
3.3.5 Change in Average Transaction Time
The X.13 AvTrtansTimeOverTime plots the av response time (blue) for transactions completed in the last 5 sec. The max response time (red) for the last 5 sec is also plotted.
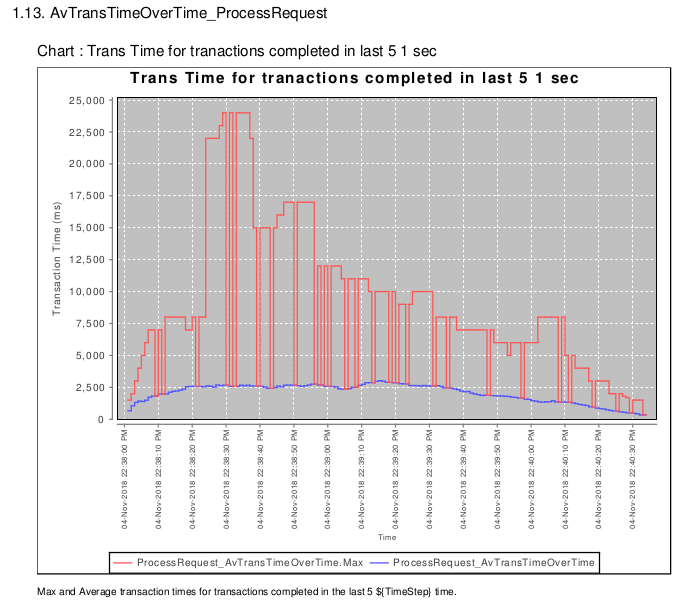
So we can see the av response was abotu 2.5sec, but there were some max responses at 22:38:30-22:38:40 that took about 25sec.
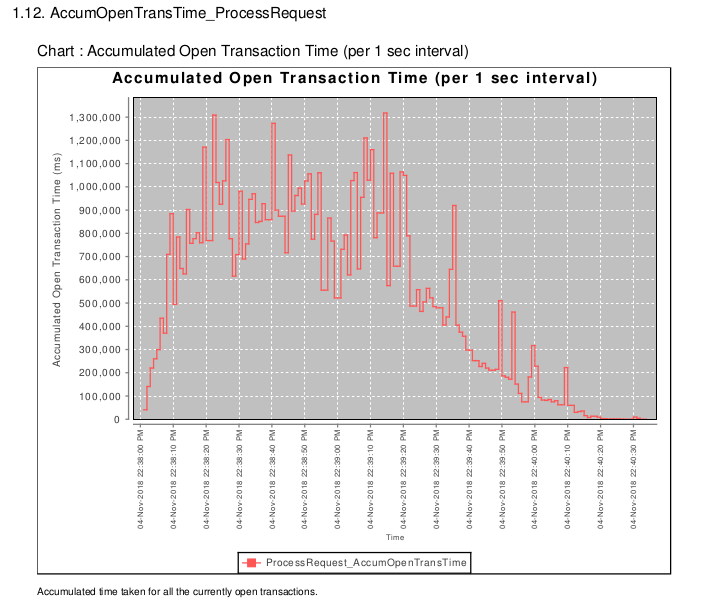
3.3.6 Accumulated Open Transaction Time
The prior graph X.11 shows the av trans time over the last 5sec, but the problem is that to give change in the av. trans time -the transactions need to have finished. And so if there is a delay introduced, there can be a delay in the av. trans time reporting it.
The X.12 Accumumulated Open Trans time was my attempt tofix that, it's a bit harder to understand, it shows the accumulated time taken for all active threads that are currently handling a transaction. If there is a bottleneck then this will more precisely pinpoint when threads started to be stopped, and when the problem occured.
3.4 Results - Long Transactions
Based on a cutoff time (10sec default) any long transactions are extracted and put in a directory, and number (the pdf report truncates at a certain length) are displayed in the pdf report. The long transactions, which in our case are fairly simple are like the following :

Where again, in our simple case, we can see the delay for this specific request was for the HTTP request.
3.4.1 A Transaction that exceeded cutoff time (24sec)
I've extracted the individual long transaction, since it gives indication of how the traces are captured and parsed.
Here is the start of the transaction, from global fragment, message-received and pre-service :
2018-11-04T22:38:06.757+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE_START: 192.168.154.1 | | [2018-11-04T22:38:06.757+11:00] | "GET /testTrace/site2" | 0 |
2018-11-04T22:38:06.757+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE_PRESERVICE: service.name=testTrace service.resolutionUri=/testTrace/* 192.168.154.1 | | [2018-11-04T22:38:06.757+11:00] | "GET /testTrace/site2" | 0 |
Then we have the individual trace elements from the policy trace, we are printing more attributes than we are using, so that could be reduced in future :
2018-11-04T22:38:06.758+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c,testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=4 assertion.shortname=Set Context Variable assertion.start=1541331486757 assertion.latency=0 status=0
2018-11-04T22:38:06.758+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c,testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=5 assertion.shortname=Set Context Variable assertion.start=1541331486758 assertion.latency=0 status=0
2018-11-04T22:38:08.058+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c,testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=7 assertion.shortname=All assertions must evaluate to true assertion.start=1541331486758 assertion.latency=1299 status=600
2018-11-04T22:38:08.058+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=13 assertion.shortname=Compare Expression assertion.start=1541331488058 assertion.latency=0 status=0
2018-11-04T22:38:08.058+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=14 assertion.shortname=Set Context Variable assertion.start=1541331488058 assertion.latency=0 status=0
2018-11-04T22:38:08.059+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=15 assertion.shortname=Set Context Variable assertion.start=1541331488058 assertion.latency=0 status=0
2018-11-04T22:38:08.059+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=12 assertion.shortname=All assertions must evaluate to true assertion.start=1541331488058 assertion.latency=1 status=0
Here is the transition that takes the longest time (and why this is captured as a long transaction) - it takes 22sec, waiting for "Route via HTTP(s) to complete:
2018-11-04T22:38:08.059+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=6 assertion.shortname=At least one assertion must evaluate to true assertion.start=1541331486758 assertion.latency=1301 status=0
2018-11-04T22:38:30.919+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=24 assertion.shortname=Route via HTTP(S) assertion.start=1541331488059 assertion.latency=22860 status=0
then we have one last step in the policy :
2018-11-04T22:38:30.919+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE: service.name=testTrace service.resolutionUri=/testTrace/* policy.name=Policy for service #310dd77d8f358c8e96f732c717b0193c, testTrace policy.guid=2c21408a-364b-4071-959f-012b78624f97 assertion.numberStr=1 assertion.shortname=All assertions must evaluate to true assertion.start=1541331486757 assertion.latency=24162 status=0
And then we trigger the post-service and message-completed global policy :
2018-11-04T22:38:30.919+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE_POSTSERVICE: service.name=testTrace service.resolutionUri=/testTrace/* 192.168.154.1 | | [2018-11-04T22:38:06.757+11:00] | "GET /testTrace/site2" | 200 | 2994
2018-11-04T22:38:30.919+1100 INFO 6261 com.l7tech.log.custom.trace: -4: TRACE_END: 192.168.154.1 | | [2018-11-04T22:38:06.757+11:00] | "GET /testTrace/site2" | 200 | 2994
3.5 Testing graph SrcLine Graph using trace.assertion.latency.
Normally I graph the "transition time" between two log entries for a particular thread, it is calculated as a delta time from the two timestamp entries on the log for the same thread id.
But API Gateway has an inbuilt default generated trace logging for API Gateway, which gives the "latency" time for the assertion.
The tool has some ability to graph values it picks up from the trace lines, so with a bit of work I was able to graph the "policy assetionStr" and the latency time. It didn't quite work out as I expected - and what follows described why.
The assertion trace log entry for API Gateway is written "after" the assertion is run. So for example if we have the following policy :
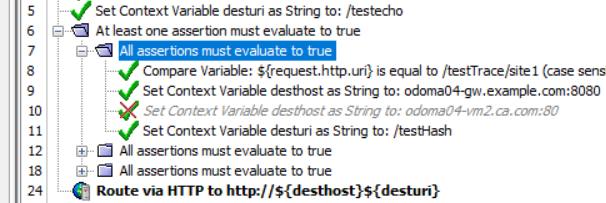
Then the order in the ssg log that will see a log entry for assertions are we will see first an entry for assertion #8, then #9, then #11 and then a entry for #7, and then #6. So this order might be the reverse of what you'd often find where trace is written on entry to a function not on exit.
The other point to make is the assertion latency printed in the trace, includes the time for all the child assertions as well. So in the above entry the latency printed with trace log entry assertion #7 is written as #7 exists, after log entry for all it's cildren were written, and "latency" entry for #7 includes the time from when #7 was started, including the time it took to run the children #8, #9, and #11, until #7 is complete.
So if we plot them we will get some of the conditional assertions with large values, which really is due to not the time spent doing the condiitonal check, but in doing all the child elements. It's a legitimate approach but you need to know 8, 9, and 11 are children of 7 to make sue of it how I was intending (or some smart calculation using starttime would also do it).
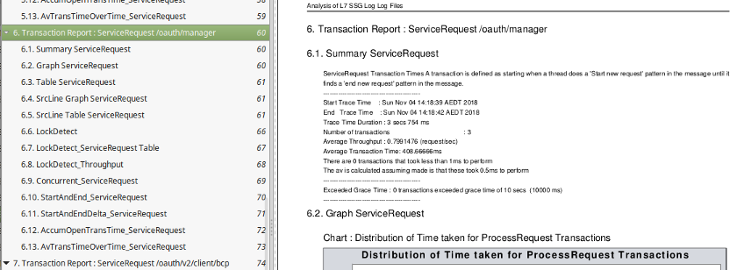
To compare "latency" report vs transition one I've used a different test run. This test run is a few calls to /oauth/manager to generate some ssg_0_0.log trace data ( the total pdf report is also attached to this report ).
Here is the summary for this test run : - so only 3 calls to service /oauth/manager taking about 400ms each.
So we ran the analysis with both using graphing latency and graphing the transition time.
3.5.1 Results - SrcLine using trace.assertion.latency time :
The results of plotting the combined (over all threads) trace.assertion.latency.time value. And then sorting according to where the most time was spent. The majority of the time reported in trace.assertion.latency is with policy state "1". So it seems to be getting into the first state or starting the transaction.

Here we have the two sample messages for that state.
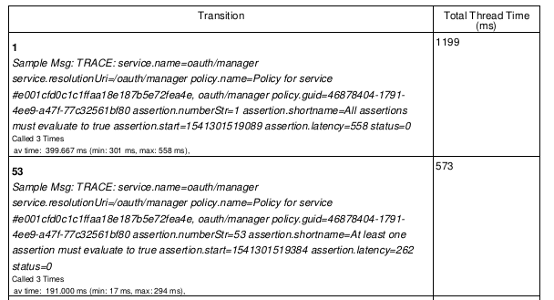
Now the issue is that assertion.latency is the time for the whole assertion, including all nested assertions.
So assertion #1, which is the base "All assertions must evaluate to true" includes the time taken for all the child assertions as well and so gives the total time for the request.
State : 1 Total Thread Time 1199 (ms)
Called 3 Times av time: 399.667 ms (min: 301 ms, max: 558 ms),
Looks like i will have to come back to this one - the data is useful and I am sure I can graph it some why - but it needs a bit more manipulation to be useful.
3.5.2 Results - SrcLine using transition time :
Here is the same SrcLine results for /oauth/manager using the "transition" approach.

And the table entry for the two transitions with the most time:
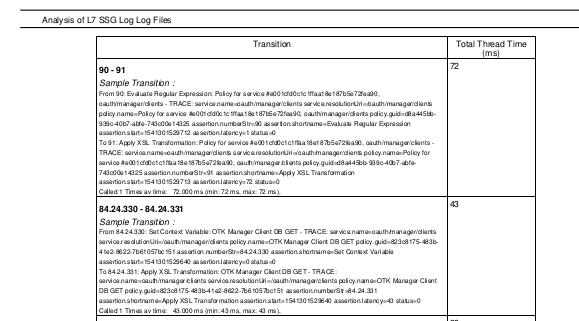
So the largest transition is (since the table is small above ) :
Transition State : 90 - 91 - total time 72ms called 1 Times av time: 72.000 ms (min: 72 ms, max: 72 ms),
Sample Transition:
From 90: Evaluate Regular Expression: Policy for service #e001cfd0c1c1ffaa18e187b5e72fea90,
oauth/manager/clients - TRACE: service.name=oauth/manager/clients service.resolutionUri=/oauth/manager/clients
policy.name=Policy for service #e001cfd0c1c1ffaa18e187b5e72fea90, oauth/manager/clients policy.guid=d8a445bb-
939c-40b7-abfe-743c00e14325 assertion.numberStr=90 assertion.shortname=Evaluate Regular Expression
assertion.start=1541301529712 assertion.latency=1 status=0
To 91: Apply XSL Transformation: Policy for service #e001cfd0c1c1ffaa18e187b5e72fea90, oauth/manager/clients -
TRACE: service.name=oauth/manager/clients service.resolutionUri=/oauth/manager/clients policy.name=Policy for
service #e001cfd0c1c1ffaa18e187b5e72fea90, oauth/manager/clients policy.guid=d8a445bb-939c-40b7-abfe-
743c00e14325 assertion.numberStr=91 assertion.shortname=Apply XSL Transformation
assertion.start=1541301529713 assertion.latency=72 status=0
And so the largest transition for /oauth/manager service is the XSL Tranformation which took 72ms to run.
Normally you would give this result in a load test, so the time is an average over all of the tests - but even for single cases it can be useful.
4. How to run It
4.1 Setup policy
4.1.1 Global Policy
We setup the following four global policy entries, for each of them we do the following:
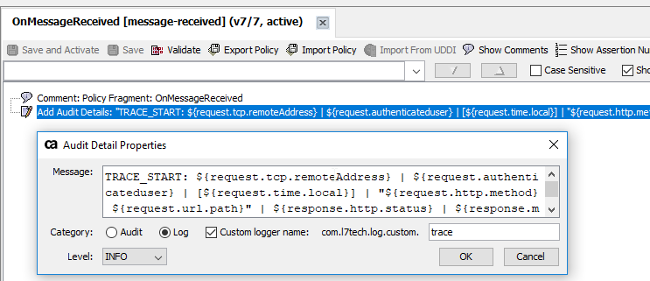
a) Add the TRACE_*** entry
b) Ensure it is write to log not audit (if we write to audit there is db connection, so write to log only likely to have less impact on the gateway performance)
c) Put in the custom logger name for all entries to be com.l7tech.log.custom.trace - makes it easier to pick out.
Note1: The policy parts are all contained in xml files attached at the of this document - once you create your global policy you can cut-and-paste the xml into the policy manger.
Note2: If you already have one of global policy you can just append these policy assertions to your existing global policy - it will have the same effect.
Note3: If you just add the OnMessageReceived, and OnMessageCompleted, and even OnPreService, and OnPostService it will still give good overall trace information without much degradation of the service.
The Global policies and their entries are : (see attachments at the end of this article, you can cut-and-paste them directly into your global & trace policies)
OnMessageReceive [message-received]
TRACE_START: ${request.tcp.remoteAddress} | ${request.authenticateduser} | [${request.time.local}] | "${request.http.method} ${request.url.path}" | ${response.http.status} | ${response.mainpart.size}
OnPreService [pre-service]
TRACE_PRESERVICE: service.name=${service.name} service.resolutionUri=${service.resolutionUri} ${request.tcp.remoteAddress} | ${request.authenticateduser} | [${request.time.local}] | "${request.http.method} ${request.url.path}" | ${response.http.status} | ${response.mainpart.size}
OnPostService [post-service]
TRACE_POSTSERVICE: service.name=${service.name} service.resolutionUri=${service.resolutionUri} ${request.tcp.remoteAddress} | ${request.authenticateduser} | [${request.time.local}] | "${request.http.method} ${request.url.path}" | ${response.http.status} | ${response.mainpart.size}
OnMessageComplete [message-completed]
TRACE_END: ${request.tcp.remoteAddress} | ${request.authenticateduser} | [${request.time.local}] | "${request.http.method} ${request.url.path}" | ${response.http.status} | ${response.mainpart.size}
4.1.2 Trace Policy
The trace policy is much the same as the global policy.
Note: it is different from the default generated trace policy - so you will need to modify it - you can cut-and-paste the .xml attachment at the end of this document);

Again, we write to log, not to audit, and to the com.l7tech.log.custom.trace logger name.
The trace log entry is :
[Internal Debug Trace Policy]
TRACE: service.name=${trace.service.name} service.resolutionUri=${trace.var.service.resolutionUri} policy.name=${trace.policy.name} policy.guid=${trace.policy.guid} assertion.numberStr=${trace.assertion.numberStr} assertion.shortname=${trace.assertion.shortname} assertion.start=${trace.assertion.start.ms} assertion.latency=${trace.assertion.latency.ms} status=${trace.status}
4.2 Enable Debug on Service
For the service you want detailed trace of click "enable policy debug trace" (bottom right of screen) .
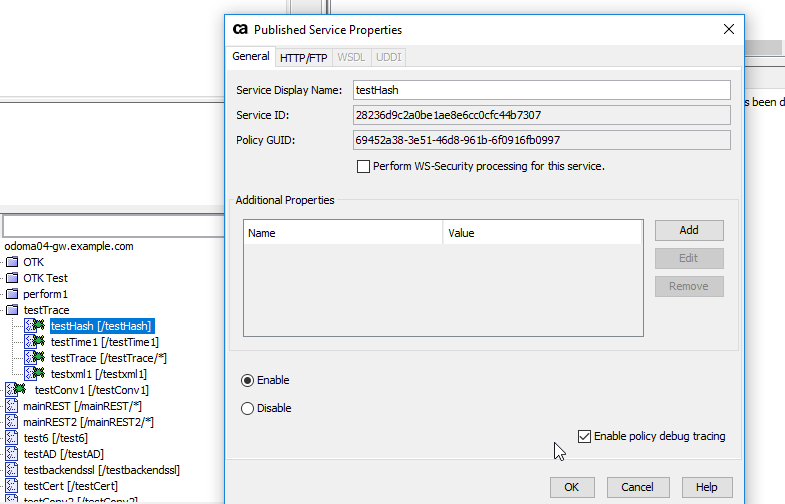
4.3 Run Load Test
I used jmeter to run the test, 700 threads, for 100 requests, here for a pretty picture for this section is one of the output reports.
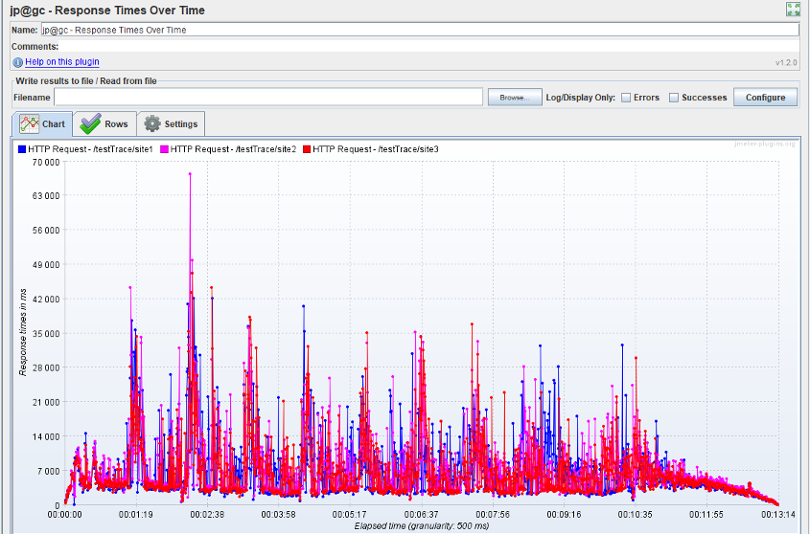
4.4 Run analysis.
4.4.1 Download SMPolicyTraceTool
From the CA community site : Siteminder Policy Trace Analysis See attachments section at end of the article, you need : SMPolicyTraceAnalysis-2_0_0-BETA-679_bin.zip or latter.
Then expand the zip file.
4.4.2 Run SmPolicyTraceTool
Then run it via click on run.bat (or run.sh) - this tends to work better than using the .jar since the .jar can often fire up the 32bit version of java. The tool can also be run from the cmd line via : runCmd.bat , thats not explained here.

4.2.2. Startup
The Program starts up blank looking as follows :
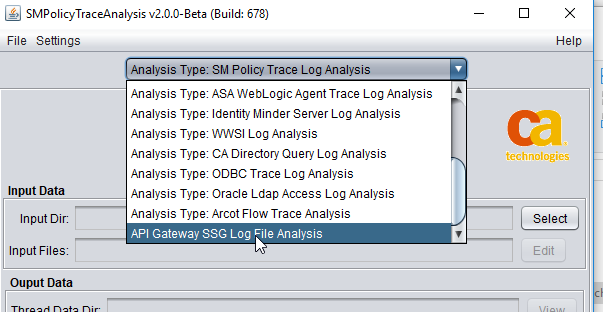
4.2.3 Select Log Type to Analyze
Yon need to set the analysis type (forgetting to do this is common mistake - I intend to code around it some day). Here we need to select the last one,
4.2.4 Select Input Directory
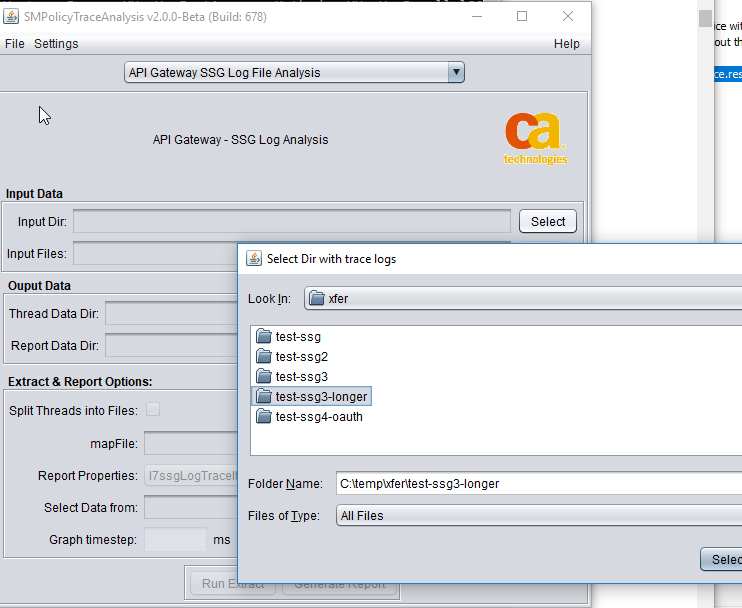
4.2.5 Select log files
The ssg log files in that directory will generally be auto selected. You can add/remove them via the buttons.
And remember to click the "sort" button (it should be automated) but is needed to get them into sorted order (the sort method checks timestamps at start/end of files and also looks for large gaps).
4.2.6 All Entered - press "Run Extract"
After entry, from the main screen you can edit the details again or select "Run" to run the analysis.
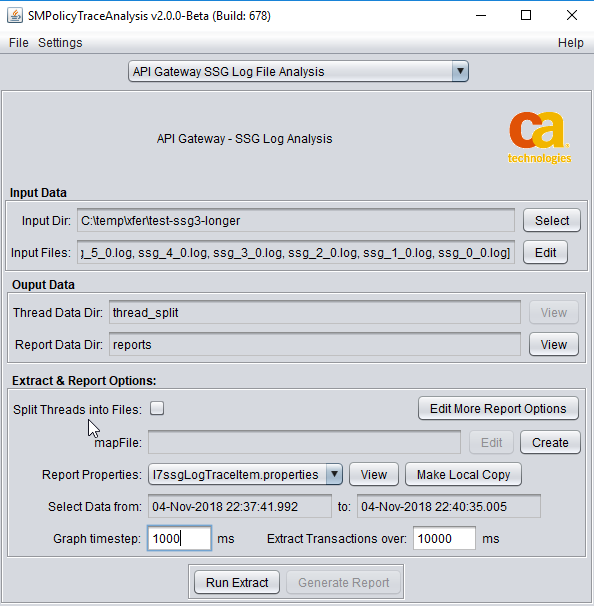
4.2.7 Processing - Progress Screen.
The run scree gives some estimate of time it will take, and also for memory usage.

4.2.8 Display Report
After run - select "PDF Report" for the pdf report, there is also a text version, and Open Rpt Dir will give you directory with extract of long or incomplete transactions.
4.2.9 View pdf report.
And hopefully now you are looking at the pdf report.
Hope this works out for you as well in analysis of performance issues.
Cheers - Mark