Server Management changed the IP addresses for our CA APM Linux servers, three servers, MOM and two collectors. After they did that, I have updated the MOM IntroscopeEnterpriseManager.properties file with the new collectors IP addresses and restarted all the EM in the three servers. Please see the screen shot attached to this case.
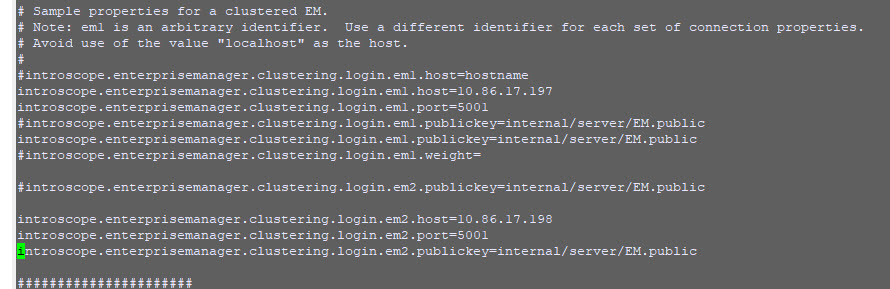
But, after making the configuration change and stopping/restarting the EM on the three servers, the two collectors were not shown under Investigator.

Then I have run the product cache clean up procedure on MOM and 2 Collectors following these steps:
1- Stop EM Enterprise Managers on the MOM and 2 collectors
2- Deleted the entire content [all files and directories] of <EM-Home>/work folder
3- Deleted the entire content [all files and directories] of /configuration folder except file config.ini path: <EM-Home>/product/enterprisemanager/configuration
4- Deleted all files at <EM-Home>/logs 5- started EM Enterprise Manager process on MOM and 2 Collectors. Started the collectors first then started the MOM. One of the collectors won't start and I am getting Database connection lost error.
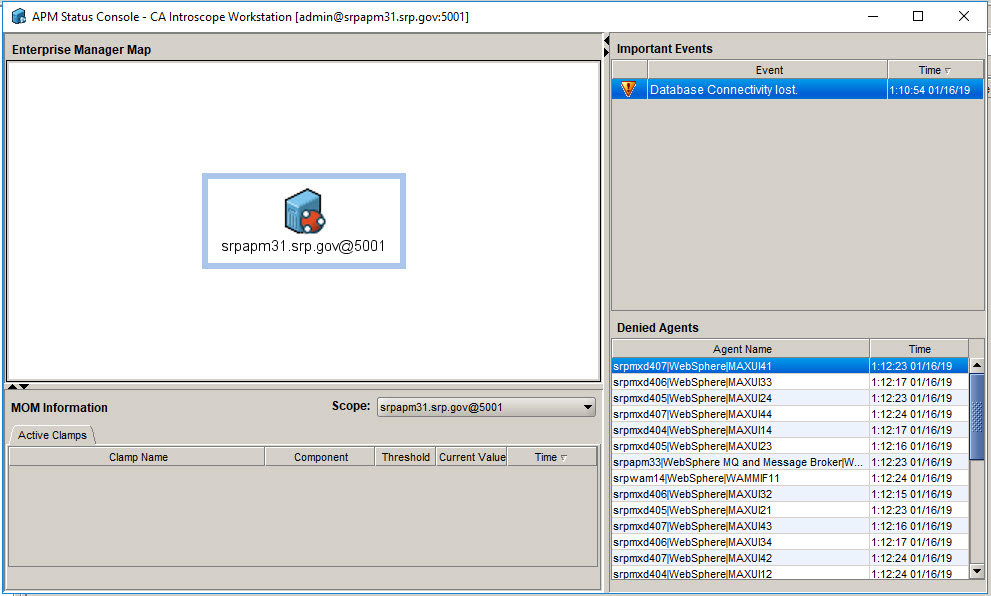
Thank you, your help will be very much appreciated
Ferhana